
Es gibt verschiedene Gründe, warum man Ordner und Dateien aus dem Filesystem in eine entsprechende Datenstruktur einlesen sollte. Der Erste ist offensichtlich: Weil man die Laufwerke, Ordner und Dateien oder auch nur Teile davon innerhalb der Datenbank anzeigen möchte, beispielsweise um zu sehen, welche Dateien zu einem bestimmten Projekt oder Kunden gehören. Der erste Schritt auf dem Weg zu einer solchen Anzeige ist das Einlesen der gewünschten Struktur – unabhängig davon, ob man den kompletten Inhalt einer Festplatte in seinen Tabellen abbilden möchte oder auch nur den Inhalt eines Unterverzeichnisses. Zum Einlesen von Laufwerken, Ordnern und Dateien gibt es verschiedene Möglichkeiten auf beiden Seiten. Auf der Seite des Dateisystems können wir mit der Dir-Funktion oder alternativ mit dem FileSystemObject arbeiten, und beim Schreiben in die Tabellen der Datenbank bietet sich unter DAO das Schreiben mit AddNew/Update oder mit der Execute-Methode an. In diesem Artikel stellen wir die schnellsten Versionen vor, damit das Einlesen umfangreicher Verzeichnis- und Dateistrukturen nicht unnötig lange dauert.
Alles oder nur einen Teil einlesen?
Technisch haben wir alle Möglichkeiten. Wir können mit den Elementen und Methoden der FileSystemObject-Klasse auf alle Laufwerke zugreifen und uns von dort auch durch die einzelnen Verzeichnisse arbeiten und schließlich die darin enthaltenen Dateien ermitteln.
Das ist jedoch nur bedingt sinnvoll, da die Datenmengen schnell riesig werden und wir den in unserer Datenbank gespeicherten Bestand möglichst synchron mit der Festplatte halten wollen. Das erfordert regelmäßige Aktualisierungen, was jeweils Minuten oder sogar Stunden dauern kann.
Also entscheiden wir uns bereits an dieser Stelle, immer nur einen Teil des Dateisystems einzulesen – in diesem Fall beginnend mit der Angabe des Verzeichnisses, dessen Inhalte wir erfassen wollen.
Den Ausgangspunkt für den zu entwickelnden Algorithmus bildet also die Auswahl des Verzeichnisses, dessen Unterelemente wir in unser Datenmodell überführen wollen.
Datenmodell für die Erfassung von Verzeichnissen und Dateien
Um die Struktur des Dateisystems bezüglich des von uns gewählten Ordners in einer Datenbank zu speichern, haben wir ebenfalls mehrere Möglichkeiten.
Wir können einfach eine Tabelle erstellen, in die wir immer den vollständigen Pfad der Verzeichnisse und Dateien schreiben. Das macht es aber aufwendiger, etwa ein TreeView mit diesen Daten zu füllen.
Wir müssten uns dann mit vielen Zeichenkettenoperationen durch die einzelnen Verzeichnisebenen eines Pfades arbeiten, was sehr viel Zeit kostet. Außerdem ist es nicht unbedingt sehr platzsparend, wenn wir immer wieder die gleichen übergeordneten Verzeichnisse in einem Datensatz ablegen.
Also wählen wir die Alternative, die aus einem Satz von drei Tabellen besteht. Hier benötigen wir zunächst eine Tabelle, um die Verzeichnisse zu speichern, beginnend mit den Verzeichnissen der ersten Ebene. Die dazu benötigten Felder lauten beispielsweise FolderID und Foldername. Damit sind wir allerdings darauf beschränkt, nur Ordnernamen speichern zu können – wir müssen also noch einen Weg finden, die Zuordnung der einzelnen Verzeichnisse zum jeweils übergeordneten Verzeichnis zu markieren.
Also fügen wir der Tabelle noch ein Feld namens ParentID hinzu, mit dem wir für einen Ordner jeweils den Datensatz mit dem übergeordneten Ordner angeben können. Wir speichern also in einer Tabelle sowohl die Ordnernamen als auch die Information über die Hierarchie dieser Ordner.
Über das Feld ParentID erzeugen wir eine reflexive Beziehung der Datensätze der Tabelle auf sich selbst. Schließlich fügen wir der Tabelle, die wir tblFolder nennen und deren Entwurf wie in Bild 1 aussieht, noch ein Feld namens UID hinzu.
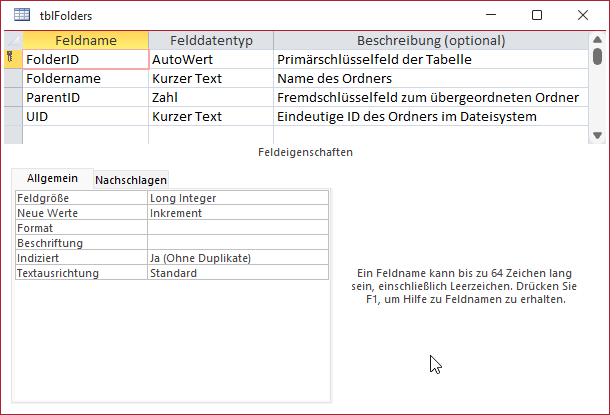
Bild 1: Tabelle zum Speichern der Ordner
In NTFS-Dateisystemen (New Technology File System), die bereits mit Windows 3.1 eingeführt wurden, können wir mit API-Funktionen eine eindeutige ID für Ordner und Dateien ermitteln. Wozu wir diese benötigen und wie wir diese auslesen, erläutern wir später.
Zunächst kümmern wir uns aber um die Tabelle zum Speichern der Dateiinformationen. Diese enthält wiederum ein Primärschlüsselfeld (FileID), ein Feld zum Speichern des Dateinamens (Filename) sowie ein Feld, mit dem wir die Beziehung zu dem Ordner herstellen, in dem sich die Datei befindet, und die wir wiederum ParentID nennen. Außerdem fügen wir auch hier ein Feld namens UID für den eindeutigen Identifizierer für die Datei sowie zwei Felder zum Speichern der Dateigröße und des Anlage- beziehungsweise letzten Änderungsdatums hinzu (siehe Bild 2).
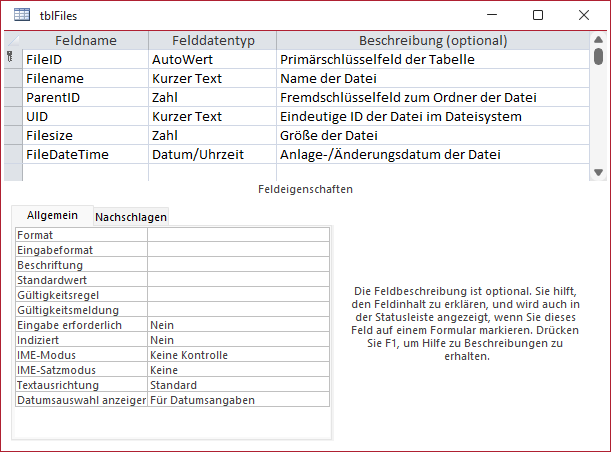
Bild 2: Tabelle zum Speichern der Dateien
Schließlich fügen wir im Beziehungen-Fenster noch die notwendigen Beziehungen hinzu (siehe Bild 3). Hier ziehen wir zunächst die Tabelle tblFolder zwei Mal hinein und erstellen eine Beziehung des Feldes ParentID des im Beziehungen-Fenster mit tblFolders_1 benannten zweiten Exemplars der Tabelle tblFolders zu dem mit tblFolder benannten Exemplar. Damit realisieren wir die Beziehung von Unterordnern zum übergeordneten Ordner. Außerdem ziehen wir noch einen Beziehungspfeil vom Feld ParentID der Tabelle tblDateien zum Feld FolderID der Tabelle tblFolders.
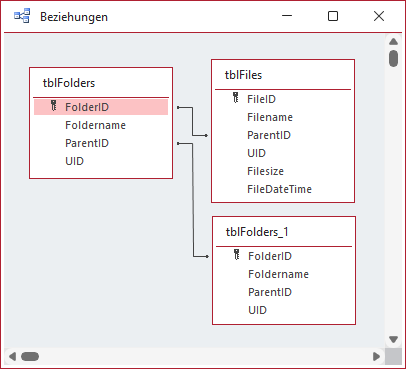
Bild 3: Beziehungen zwischen den Tabellen
Einlesen der Ordner und Dateien
Die intuitive Vorgehensweise zum Einlesen der Ordner und Dateien des gewünschten Ordners würde sich nach dem Aufbau des Dateisystems und unserer Tabellenstruktur richten.
Wir würden also etwa die Klassen und Methoden der FileSystemObject-Klasse nutzen, um ausgehend vom Basisordner zunächst die darin enthaltenen Ordner einzulesen und in die Tabelle tblOrdner zu schreiben. Beim Durchlaufen dieser Ordner würden wir in einer rekursiven Prozedur die untergeordneten Ordner und die Dateien dieses Ordners einlesen und so weiter.
Diese Vorgehensweise ist jedoch nicht schnell genug. Beim Einlesen umfangreicher Ordnerstrukturen wollen wir schließlich nicht ewig warten. Deshalb wählen wir hier einen alternativen Ansatz, der allerdings etwas komplexer ist und wie in Listing 1 beginnt.
Public Sub OrdnerUndDateienEinlesen(ByVal strRoot As String) Dim wrk As DAO.Workspace Dim db As DAO.Database Dim rstFolders As DAO.Recordset Dim rstFiles As DAO.Recordset Dim colTodo As Collection Dim strPfad As String Dim strEintrag As String Dim strVollPfad As String Dim lngAttr As Long Dim lngCounter As Long Dim strUID As String Dim lngParentID As Long Dim lngCurrentFolderID As Long Dim lngTimer As Long Dim booIsRoot As Boolean lngTimer = Timer If Right$(strRoot, 1) = "\" Then strRoot = Left$(strRoot, Len(strRoot) - 1) End If Set wrk = DBEngine(0) Set db = wrk.Databases(0) Call TabellenZuruecksetzen(db) Set rstFolders = db.OpenRecordset("tblFolders", dbOpenDynaset) Set rstFiles = db.OpenRecordset("tblFiles", dbOpenDynaset) Set colTodo = New Collection Call TodoAdd(colTodo, strRoot, 0) bolIsRoot = True DoCmd.Echo False DoCmd.Hourglass True wrk.BeginTrans On Error GoTo Fehler ...
Listing 1: Die Prozedur OrdnerstrukturEinlesen (Teil 1)
Was macht die Prozedur OrdnerUndDateienEinlesen überhaupt?
- Wir haben einen Startordner (zum Beispiel C:\Buecher).
- Darin sind Unterordner und Dateien.
- In den Unterordnern sind wieder Unterordner und Dateien. Das Ganze als Baum.
- Die Prozedur läuft durch den ganzen Baum, schreibt alle Ordner in tblFolders, schreibt alle Dateien in tblFiles, merkt sich zu jeder Datei und jedem Ordner, wo sie liegen (ParentID), und speichert außerdem eine UID (damit wir sie später wiedererkennen) und Größe und Datum (für Dateien).
Danach können wir mit diesen Tabellen bequem arbeiten, zum Beispiel zum Füllen eines TreeView-Steuerelements.
Die Prozedur OrdnerUndDateienEinlesen Schritt für Schritt erklärt
Die Prozedur bekommt mit dem Parameter strRoot einen Startpfad. Als Erstes deklarieren wir die Variablen:
- wrk und db: Verweise auf die aktuelle Datenbank und das Workspace-Objekt
- rstFolders und rstFiles: Recordsets für tblFolders und tblFiles
- colTodo: Eine Collection als To-do-Liste mit Ordnern, die noch abgearbeitet werden müssen
- strPfad, strEintrag und strVollPfad: String-Variablen für aktuelle Pfade/Namen
- lngAttr: Dateiattribute (ist es ein Ordner oder eine Datei?)
- lngCounter: Wieviele Dateien haben wir schon gefunden?
- strUID: Datei-/Ordner-ID, die wir mit der Funktion GetFileID holen
- lngParentID und lngCurrentFolderID: Verweise auf übergeordnete Ordner
- lngTimer: Erfassung der Laufzeit
- booIsRoot: Gibt an, ob wir noch im Root-Ordner sind
Zu Beginn speichern wir den aktuellen Timer-Wert in lngTimer, um später die Gesamtzeit für den Vorgang ausgeben zu können. Außerdem schneiden wir vom Root-Ordner in strRoot noch ein eventuell am Ende befindliches Backslash-Zeichen ab, falls dieses noch vorhanden ist.
Workspace und Transaktion für schnelleres Schreiben
Danach initialisieren wir die Workspace-Variable wrk und die Database-Variable db. Das Workspace-Objekt benötigen wir, weil wir damit die vielen Anlegevorgänge in einer Transaktion bündeln können, was wesentlich schneller funktioniert, als wenn wir jeden Vorgang einzeln durchführen.
Tabellen zurücksetzen und leeren
Danach rufen wir die Prozedur TabellenZuruecksetzen auf. Diese löscht nicht nur einfach die Daten, sondern fügt zuvor einen neuen Datensatz in die beiden Tabellen tblFolders und tblFiles ein, der im Primärschlüsselfeld den Wert 0 enthält. Damit setzen wir den Autowert der beiden Tabellen zurück, sodass beim Neuanlegen von Datensätzen nachfolgend wieder mit dem Wert 1 gestartet wird. Anschließend löschen wir alle Datensätze aus diesen beiden Tabellen:
Public Sub TabellenZuruecksetzen(db As DAO.Database) db.Execute _ "INSERT INTO tblFiles(FileID, Filename) " _ & "VALUES(0, '''')", dbFailOnError db.Execute _ "INSERT INTO tblFolders(FolderID, Foldername) " _ & "VALUES(0, '''')", dbFailOnError db.Execute "DELETE FROM tblFiles", dbFailOnError db.Execute "DELETE FROM tblFolders", dbFailOnError End Sub
Weitere Initialisierungen
Danach öffnen wir zwei Recordsets: rstFolders für die Ordner und rstFiles für die Dateien. Außerdem legen wir ein Collection-Objekt namens colToDo an, mit dem wir noch zu bearbeitende Ordner speichern.
Hier legen wir als Erstes den Startordner aus dem Parameter strRoot mit dem Wert 0 ab. Das geschieht in einer weiteren Hilfsprozedur namens TodoAdd.
Dieser übergeben wir das Collection-Objekt, den Pfad und die ID des übergeordneten Ordners als Parameter.
Wir fügen der Collection dann einen Eintrag hinzu, der aus der ID des übergeordneten Ordners, dem Pipe-Zeichen (|) und dem Pfad besteht. Im ersten Aufruf tragen wir also den Wert 0|[Pfad] ein:
Private Sub TodoAdd(ByRef col As Collection, _ ByVal strPfad As String, ByVal lngParentID As Long) col.Add CStr(lngParentID) & "|" & strPfad End Sub
Der Wert 0 bedeutet in diesem Fall, dass es keinen übergeordneten Ordner gibt.
Da dieser erste Ordner eine Spezialbehandlung erfahren soll, stellen wir außerdem die Variable bolIsRoot auf True ein.
Schließlich deaktivieren wir die Bildschirmaktualisierung mit DoCmd.Echo False und aktivieren die Sanduhr mit DoCmd.Hourglass True.
Starten der Transaktion und der Do While-Schleife
Nun starten wir die Transaktion und integrieren die Fehlerbehandlung (siehe Listing 2).
...
Do While colTodo.Count > 0
Call TodoPop(colTodo, strPfad, lngParentID)
If Right$(strPfad, 1) <> "\" Then
strPfad = strPfad & "\"
End If
If Not bolIsRoot Then
rstFolders.AddNew
rstFolders!FolderName = GetFolderNameFromPath(strPfad)
If lngParentID > 0 Then
rstFolders!ParentID = lngParentID
Else
rstFolders!ParentID = Null
End If
rstFolders!UID = GetFileID(strPfad)
lngCurrentFolderID = rstFolders!FolderID
rstFolders.Update
Else
lngCurrentFolderID = 0
bolIsRoot = False
End If
strEintrag = Dir$(strPfad & "*", vbDirectory)
Do While strEintrag <> ""
If strEintrag <> "." And strEintrag <> ".." Then
strVollPfad = strPfad & strEintrag
strUID = GetFileID(strVollPfad)
If Len(strUID) > 0 Then
lngAttr = GetAttr(strVollPfad)
If (lngAttr And vbDirectory) = vbDirectory Then
Call TodoAdd(colTodo, strVollPfad, lngCurrentFolderID)
Else
rstFiles.AddNew
rstFiles!FileName = strEintrag
rstFiles!ParentID = lngCurrentFolderID
rstFiles!UID = strUID
rstFiles!Filesize = FileLen(strVollPfad)
rstFiles!FileDateTime = FileDateTime(strVollPfad)
rstFiles.Update
lngCounter = lngCounter + 1
End If
End If
End If
strEintrag = Dir$()
Loop
...
Listing 2: Die Prozedur OrdnerstrukturEinlesen (Teil 2)
Anschließend starten wir eine Do While-Schleife, in der wir alle Elemente der Collection colToDo durchlaufen. Die Informationen aus der Collection holen wir uns mit der Hilfsfunktion ToDoPop:
Private Sub TodoPop(ByRef col As Collection, _ ByRef strPfad As String, ByRef lngParentID As Long) Dim v As Variant Dim p As Long v = col(1) col.Remove 1 p = InStr(1, v, "|") lngParentID = CLng(Left$(v, p - 1)) strPfad = Mid$(v, p + 1) End Sub
Sie schreibt den ersten Eintrag der Collection in die Variant-Variable v und entfernt dieses Element aus der Collection.
Dann liest sie die Position des Pipe-Zeichens mit der InStr-Funktion aus und schreibt anschließend den Teil vor dem Pipe-Zeichen in den Rückgabeparameter lngParentID und den Teil dahinter in den Rückgabeparameter strPfad.
Danach prüfen wir, ob der Pfad einen abschließenden Backslash enthält, und fügen diesen gegebenenfalls an.
Ordner in tblFolders eintragen
Nun folgt in einer If…Then-Bedingung die Unterscheidung, ob wir gerade mit dem Root-Ordner arbeiten (bolIsRoot ist dann True) oder ob wir bereits in einer untergeordneten Ebene gelandet sind.
Im Falle des Root-Ordners tragen wir lediglich den Wert 0 in die Variable lngCurrentFolderID ein und setzen bolIsRoot auf False.
Falls wir bereits einen untergeordneten Ordner bearbeiten, speichern wir diesen direkt in der Tabelle tblFolders. Dazu rufen wir die AddNew-Methode von rstFolders auf und tragen die Werte ein. Für das Feld FolderName ermitteln wir den letzten Teil des Pfads mit der Funktion GetFolderNameFromPath, die wie folgt aussieht:
Private Function GetFolderNameFromPath( _ ByVal strPfad As String) As String If Right$(strPfad, 1) = "\" Then strPfad = Left$(strPfad, Len(strPfad) - 1) End If GetFolderNameFromPath = _ Mid$(strPfad, InStrRev(strPfad, "\") + 1) End Function
Die Funktion erhält den Pfad aus strPfad als Parameter und entfernt zunächst ein eventuell vorhandenes abschließendes Backslash-Zeichen.
Dann lesen wir den Teil des Pfades hinter dem letzten vorhandenen Backslash-Zeichen ein und geben diesen als Funktionsergebnis zurück.
Außerdem tragen wir die FolderID des übergeordneten Ordners in das Feld ParentID und die eindeutige ID des Ordners aus dem NTFS-System in das Feld UID.
Diese ermitteln wir mit der Funktion GetFileID, die wir weiter unten beschreiben.
In der Variablen lngCurrentFolderID speichern wir schließlich den Primärschlüsselwert des neuen Datensatzes. Diesen benötigen wir, um weitere untergeordnete Ordner- und Dateidatensätze mit dem angelegten Eintrag in tblFolders verknüpfen zu können.
Dateien und Unterordner des aktuellen Ordners einlesen
Nun holen wir uns mit der Dir-Funktion den ersten Unterordner des Ordners aus strPfad. Damit Dir tatsächlich nur Ordner liefert und keine Dateien, geben wir als zweiten Parameter den Wert vbDirectory an.
Wenn die so befüllte Variable strEintrag keine leere Zeichenkette enthält, steigen wir in die folgende Do While-Schleife ein, die genau dies als Abbruchkriterium nutzt.
Nur für Abonnenten
Ab hier wird’s wirklich spannend – der Rest ist exklusiv für Abonnenten.
Mit dem Abo von Access im Unternehmen bekommst du den kompletten Artikel – inklusive vollständigem Code, Beispieldatenbank und Schritt-für-Schritt-Erklärung.
So sparst du dir stundenlanges Herumprobieren, vermeidest teure Fehler in deiner Access-Anwendung und kannst Lösungen direkt in deinem Unternehmen einsetzen, statt nur darüber zu lesen.
Teste Access im Unternehmen jetzt 4 Wochen lang kostenlos: Voller Zugriff auf alle Artikel, Downloads und Beispieldatenbanken. Kein Risiko – wenn es für dich nicht passt, kündigst du einfach innerhalb der ersten vier Wochen.
Bereits Abonnent? Hier einloggen
Kostenlos & unverbindlich
Oder hast Du eine konkrete Frage zu Deiner eigenen Access-Anwendung?
Vielleicht stellt Deine Anwendung Dich vor eine Herausforderung, zu der Du bisher keine Lösung findest. Schlechte Performance, kein ausreichender Zugriffsschutz, Du bist unsicher über Dein Datenmodell oder Dein Code liefert unerklärliche Fehler?
In unserem kostenlosen Access-Audit schaut sich André Minhorst persönlich gemeinsam mit Dir Deine Lösung per Zoom an – und zeigt Dir, wo Datenmodell, VBA-Code, Ergonomie und Sicherheit Optimierungspotenzial bieten.
Jetzt kostenloses Access-Audit anfordern →