
Hierarchieartige Strukturen spielen im Datenbankentwurf immer wieder eine große Rolle. Bereits eine schlichte 1:n-Beziehung stellt eine Hierarchie dar. Um in der Dateneingabe einerseits flexibel zu bleiben, aber dennoch Benutzerfehler schon durch den Entwurf zu verhindern, muss man einige Dinge beachten. In diesem Beitrag zeigen wir die Fallstricke beim Entwurf hierarchischer Datenstrukturen auf.
Bei diesen Fragen stehen drei Themen im Mittelpunkt:
- Die Datenmodellierung: Welche Tabellen, welche Felder
- Die Abfragetechnik: Wie kommen Sie an gewünschte Informationen heran
- Die Präsentation: Wie stellen Sie die Daten übersichtlich dar
In diesem Artikel geht es zunächst um den ersten Teil, die Datenmodellierung.
Hierarchien
Es gibt mehrere Arten von Hierarchien, die sich zunächst in Begriffshierarchien und Objekthierarchien aufteilen:
Begriffshierarchien oder logische Hierarchien liegen vor, wenn die Objekte, die Sie in Form von Datensätzen verwalten wollen, in einem Teil der zu speichernden Eigenschaften übereinstimmen, sich aber in anderen unterscheiden. Dabei geht es nicht um die Eigenschaftsausprägungen, also die Feldwerte, sondern um die Eigenschaften an sich beziehungsweise die Felddefinitionen.
Nehmen wir an, Sie haben es in Ihrer Datenbank mit Firmen zu tun, die sich in Kunden und Lieferanten aufteilen. Um Beziehungen mit referentieller Integrität zu anderen Tabellen des Modells umzusetzen (etwa Kunde/Auftrag, Lieferant/Bestellung), brauchen Sie eine Lieferantentabelle und eine Kundentabelle. Sie benötigen durchaus unterschiedliche Informationen zu beiden – zu den Lieferanten erfassen Sie etwa Lieferrabatte oder durchschnittliche Lieferzeiten, zu den Kunden erfassen Sie Informationen, die für die Akquise wichtig sind und die Sie in Zusammenhang mit Lieferanten nie brauchten.
Die Felddefinitionen beider Tabellen sind jedoch zu einem großen Teil identisch: Sowohl Kunden als auch Lieferanten definieren sich über einen Namen, eine Stammadresse und andere Informationen, denn sie gehören der gleichen Grundmenge an: den Firmen.
Hier haben wir nun eine einstufige Begriffshierarchie: Firma – (Kundenfirma, Lieferantenfirma).
Es gibt ein Feldbündel, das für Firmen generell gilt, und es gibt je ein Feldbündel, das speziell nur für Kunden oder Lieferanten gilt. So etwas nennt man Generalisierungs-Spezialisierungs-Struktur. In der objektorientierten Programmierung gibt es ähnliches, dort ist dafür die Bezeichnung IsA-Beziehung („Ist-Ein-Beziehung“) üblich. Klassenprogrammierer modellieren so etwas mit Vererbung von Klassen.
Implementieren von Begriffshierarchien
Wie aber modelliert ein Datenbankprogrammierer diese Beziehung in einer Tabellenstruktur Nun, genau hier kommen die oft verkannten 1:1-Beziehungen zum Einsatz. Genauer sind es 1:1/0-Beziehungen: sie sind also nicht symmetrisch. Es gibt eine Mastertabelle, die 1-Seite, die die Felder für die höhere Generalisierungsstufe aufnimmt (im Beispiel die Firma), und Detailtabellen, die 1/0-Seite, die die Felder für die stärker spezialisierten Stufen aufnehmen – im Beispiel Kunde und Lieferant.
Solche Hierarchien können natürlich auch mehrstufig werden. Ein Beispiel ist die biologische Systematik: Reich/Stamm/Klasse/Ordnung/Familie/Gattung/Art:
– Wirbeltiere
– Fische
– Reptilien
– Vögel
– Säugetiere
– Paarhufer
– Unpaarhufer
– Raubtiere
– Nagetiere
Die anzulegenden Tabellen tragen dabei nicht etwa die Namen Klasse, Ordnung, Familie, Gattung und Art, sondern Sie müssen tatsächlich eine Tabelle Wirbeltiere für die Eigenschaften, die allen Wirbeltieren gemeinsam sind, anlegen. Damit nicht genug: Es gibt weitere Spezialtabellen namens Fische, Reptilien, Vögel und Säuger und dann in einer weiteren Stufe noch Spezialtabellen zweiter Ordnung wie Huftiere und Raubtiere oder bei den Reptilien Schlangen, Eidechsen und Schildkröten.
Umfangreiche Begriffshierarchien erfordern also eine Vielzahl von Tabellen. Zum Glück sind die meisten derartigen Hierarchien in betriebswirtschaftlichen Anwendungen sehr flach, sodass sich die Tabellenzahl in Grenzen hält.
Der Aufbau der Tabellen ist nicht sonderlich schwer: Auf der obersten Ebene wird ein Schlüsselfeld angelegt (zum Beispiel ein Autowert-Feld) sowie Felder für alle Daten, die allen Individuen gemeinsam sind. Die Tabellen der zweiten Ebene enthalten als Primärschlüssel ein Feld, das die Beziehung zum Primärschlüssel der ersten Ebene aufbaut. Im Falle eines Autowertes auf oberster Ebene verwenden Sie hier eine Long-Integer-Zahl. Diese vererbt sich auf alle nachgeordneten Ebenen. Hinzu kommen die spezifischen Daten dieser Ebene. Die verschiedenen Tabellen auf einer Ebene haben dabei durchaus völlig unterschiedliche Felder, was ja letztlich der Grund für die Aufteilung auf mehrere Tabellen ist. Für die weiteren Ebenen setzt sich dies analog fort.
Sie könnten nun auf die Idee kommen, einfach eine Tabelle Tiere anzulegen, die alle Felder enthält oder, um ein praxisnäheres Beispiel zu verwenden, nur eine Tabelle namens Firmen, die Kunden- und Lieferantenfelder mit aufnimmt. Dadurch entstehen jedoch verschiedene Probleme.
Die Tabelle Tiere würde jetzt unter anderem die Felder Fellfarbe und Flossenform enthalten. Dadurch bleibt bei allen Nichtfischen das Feld mit den Flossen leer und kein Nichtsäuger braucht das Feld zum Eintragen einer Fellfarbe.
Dadurch wird zunächst die NULL-Wert-Semantik ruiniert, da NULL jetzt nicht mehr wie gefordert für prinzipiell existierende, aber noch nicht bekannte Daten steht, sondern für Daten, die gar nicht existieren können.
Angenommen keines dieser spezialisierten Felder würde zwingend eine Eingabe erfordern. Dann können Sie, wenn keines dieser Felder ausgefüllt ist, nicht mehr unterscheiden, um welche spezielle Gruppe es sich handelt. Also brauchen Sie ein Typfeld, das diese Information liefert. Der Benutzer kann dann aber problemlos die Kategorie Fisch auswählen und dazu die Fellfarbe ausfüllen. Ergo: Die Datenbank bietet die strukturelle Möglichkeit, widersprüchliche Informationen einzugeben.
Wenn nun eines oder mehrere solcher Felder zwingend eine Eingabe erfordern, zum Beispiel die Fellfarbe bei Säugetieren, tritt das erste Problem auf: Sie können das Feld nicht auf Eingabe erforderlich stellen, da dieses etwa bei Fischen nicht ausgefüllt werden darf.
Und schließlich stellt sich noch ein weiteres Problem: Zwischen Teilen dieser zusammengewürfelten Tabelle und anderen Tabellen sollen Beziehungen bestehen. Zum Beispiel wollen Sie eine Beziehung zwischen Kunden und Aufträgen und zwischen Lieferanten und Bestellungen herstellen. Wenn beide zusammen in einer Tabelle namens Firmen gespeichert sind, steht diese auf der einen Seite der Beziehung.
Das Datenbanksystem kann nun aber Fehleingaben wie die Zuordnung eines Lieferanten zu einem Auftrag nicht mehr über referentielle Integrität verhindern. Fehleingaben kann man hier nicht mehr durch die reine Tabellenstruktur, sondern nur noch durch eine entsprechende Programmierung vermeiden.
Die Variante mit je einer Lieferanten- und Kundentabelle vermeidet diese Probleme, ersetzt sie aber durch neue.
Eine Liste aller Firmen erhalten Sie beispielsweise nur über eine UNION-Abfrage auf Teile dieser Tabellen. Für Firmen, die gleichzeitig Lieferant und Kunde sind – das kann es ja durchaus geben -, gäbe es direkt zwei Datensätze, je einen in der Lieferanten- und in der Kundentabelle. Dies führt dazu, dass änderungen der Firmendaten an mehreren Stellen notwendig sind. Bei Verwendung von Autowerten hat dieselbe Firma als Kunde und Lieferant verschiedene Primärschlüssel. Durch einen Vertipper im Firmennamen bei der doppelten Eingabe entstehen inkonsistente Daten.
Somit bleibt nur die Möglichkeit, Begriffshierarchien auch regelgerecht mit 1:1/0-Beziehungen aufzubauen.
Es ist natürlich legitim, durch Wahl abstrakterer Begriffe für die Felder die Tabellenanzahl möglichst klein zu halten. Zum Beispiel könnten Sie statt der Felder Fellfarbe (Säuger), Schuppenfarbe (Fische) oder Federfarbe (Vögel) die zwei Felder Farbe und Ummantelungsart auf der Ebene Tier verwenden.
Arten von Begriffshierarchien
Man kann mehrere Sorten von Spezialisierungen unterscheiden:
- Optional: Es kann Detaildatensätze geben.
- Obligatorisch: Es gibt einen Datensatz in mindestens einer Detailtabelle.
- Disjunkt: Es darf einen Datensatz in höchstens einer Detailtabelle geben.
- Adjunkt: Es darf je einen Datensatz in mehreren Detailtabellen geben.
Das Tierbeispiel ist disjunkt obligatorisch. Jedes Tier gehört zu je einer Klasse, Ordnung, Familie, Gattung und Art. Sie können zu einem Tier nicht einfach Teile der Hierarchie weglassen. Obendrein gehört jedes Tier zu höchstens einer Klasse, Ordnung, Familie, Gattung und Art. Es darf also nicht mehreren Tabellen auf derselben Ebene zugeordnet sein.
Das Firmenbeispiel ist adjunkt optional. Eine Firma braucht weder Lieferant noch Kunde zu sein („sonstige Firma“), kann eines davon sein, aber auch beides zugleich.
Aus den beiden Eigenschaftenpaaren lassen sich also vier Typen kombinieren. Das Festlegen eines davon ist über Trigger möglich. Ohne weitere Trigger hat man den Typ adjunkt optional eingestellt.
Das Fehlen von Triggern ist natürlich ein schweres Manko von Access, insbesondere da diese per definitionem Bestandteil eines RDBMS sein müssen. Es bleibt hier nur der Notnagel, Trigger in den Eingabeformularen per Ereignisse und VBA-Code nachzustellen und den Zugriff anderer Clients ohne diese Kontrolle auf die Daten zu verhindern.
Dieses Ungemach ist natürlich jedem Access-Entwickler vertraut, man kann es allenfalls durch einen SQL-Server oder eine vergleichbare Datenbankmaschine als Backend umgehen.
Zusammenfassung
Durch ein richtiges Modell ergeben sich folgende Vorteile:
- Zu einem Datensatz existieren keine systematisch leeren Felder, daher kann auch keiner annehmen, diese Werte müsse es geben und sie seien nur noch nicht gefüllt.
- Typspezifische Pflichtfelder sind möglich.
- Der Typ wird daran erkannt, in welcher Detailtabelle ein Datensatz vorliegt.
- Die NULL-Wert-Semantik bleibt gewahrt.
In Bild 1 sehen Sie, wie sich die zahlreichen Datensätze der obersten Ebene auf immer mehr spezialisierte Tabellen verteilen. Die Anzahl Tabellen wird je Ebene immer größer, die Anzahl Datensätze in den Tabellen dabei kleiner. Letztlich zieht sich ein Datensatz einfach über mehrere Tabellen hin; erkennbar an der Graufärbung bei einigen Beispieldatensätzen.
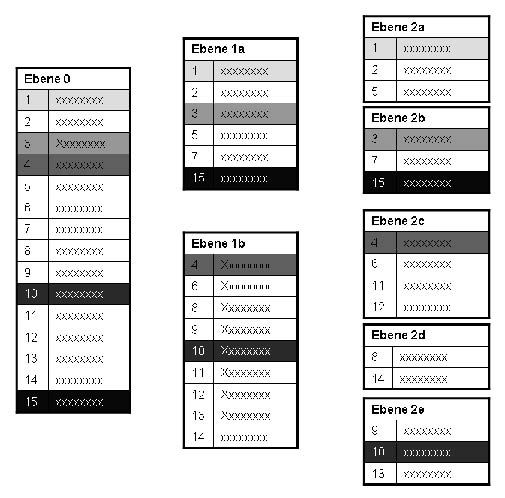
Bild 1: Begriffshierarchie
Objekthierarchien
Eine Objekthierarchie oder auch materiale Hierarchie wie in Bild 2 liegt vor, wenn die Objekte, die Sie in Form von Datensätzen verwalten wollen, zueinander in einem Über-Unter-Ordnungsverhältnis stehen. Die Eigenschaften der Objekte, die sich als Tabellenfelder niederschlagen, sind dabei zunächst irrelevant; entscheidend ist die mögliche Existenz mehrerer abhängiger Datensätze zu einem Datensatz auf der nächsten Ebene, was analog auch für weitere Ebenen gilt.
Nehmen wir an, Sie haben in Ihrer Datenbank Firmen, deren Angestellte für Sie als Ansprechpartner fungieren, die wiederum mit Ihnen jeweils mehrere Gespräche führen.
Eine Firma regiert also beliebig viele Ansprechpartner, von denen jeder beliebig viele Gespräche regiert. Umgekehrt können Sie jedes Gespräch genau einer Person zuordnen und diese wiederum genau einer Firma.
Im Gegensatz zur Begriffshierarchie zerfasern die Tabellen also nicht beim Durchlaufen der Ebenen, sondern es gibt auf jeder Ebene nur eine Tabelle. Allerdings zerfasern hier die Datensätze, im typischen Fall gehören also zu jedem Datensatz auf der nächsten Ebene mehrere Datensätze. Der Hierarchiecharakter zeigt sich also bei der Begriffshierarchie auf Tabellenebene und hier, bei der Objekthierarchie, auf Datensatzebene.
In der Klassenprogrammierung entspricht dieser Art der Hierarchie die mehrfache Instanzierung, wobei eine Oberklasse über eine Listeneigenschaft verfügt, die mehrere Unterklassen derselben Art referenziert.
Arten von Objekthierarchien
Auch bei den Objekthierarchien gibt es mehrere Hierarchietypen:
- Reflexiv: Die Hierarchie ist selbstbezüglich; in der Folge müssen die Objekte aller Ebenen vom gleichen Typ sein (siehe Bild 3).
- Irreflexiv: Die Hierarchie ist nicht selbstbezüglich.
- Finit (geschlossen): Es gibt eine feste Anzahl Hierarchieebenen, die sich nie ändert.
- Infinit (offen): Die Ebenen können beliebig tief geschachtelt sein.
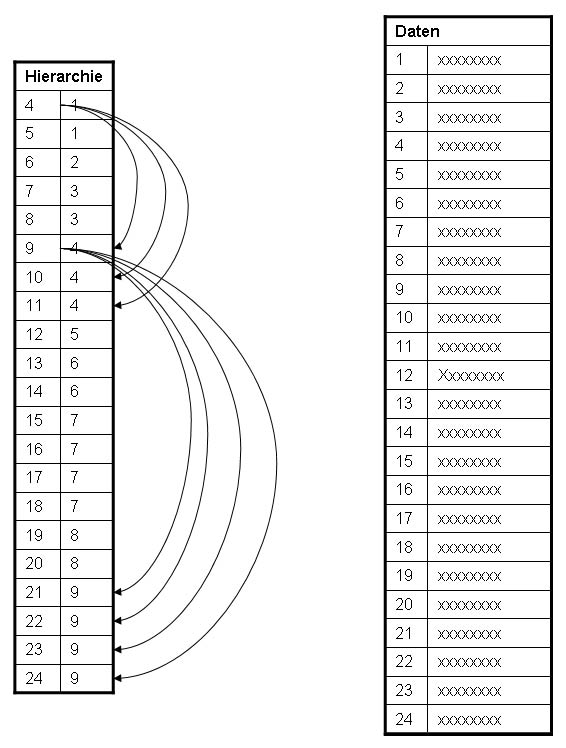
Bild 3: Reflexive Objekthierarchie
Aus diesen beiden Eigenschaftenpaaren lassen sich diesmal nur drei Typen kombinieren. Eine finite Hierarchie kann reflexiv oder irreflexiv sein; eine infinite Hierarchie ist aber nur reflexiv möglich.
Implementieren der Hierarchiearten
Geschlossene irreflexive Hierarchien sind der häufigste Fall in der Datenbankentwicklung. Diese legen Sie einfach in Form aufeinander folgender 1:n-Beziehungen an. Ebene 1 wiederholt den Primärschlüssel von Ebene 0 als Fremdschlüssel; Ebene 2 wiederholt den Primärschlüssel von Ebene 1 als Fremdschlüssel und so weiter.
Jede dieser Tabellen kann von anderer Bedeutung sein und andere Datenfelder enthalten als vorgängige und nachfolgende Ebenen. Die Fremdschlüsselfelder müssen mit Eingabezwang versehen werden, da sonst nicht sichergestellt ist, dass alle Elemente bis auf die gleiche Ausgangsebene („Wurzel“) zurückverfolgt werden können.
Ende des frei verfügbaren Teil. Wenn Du mehr lesen möchtest, hole Dir ...
den kompletten Artikel im PDF-Format mit Beispieldatenbank
diesen und alle anderen Artikel mit dem Jahresabo