
Lies diesen Artikel und viele weitere mit einem kostenlosen, einwöchigen Testzugang.
Spätestens dann, wenn Sie eine Datenbank zum Kunden geben, gibt es zwei Versionen der gleichen Datenbank. Meist geschieht dies bereits viel früher – zum Beispiel, wenn Sie eine Sicherheitskopie eines bestimmten Entwicklungsstands der Datenbank anfertigen, um ohne Sorge änderungen vornehmen zu können. Was aber, wenn Sie etwa nach Arbeiten am Datenmodell noch einmal prüfen möchten, wie die Unterschiede zum Datenmodell einer anderen Version der Datenbank aussehen Genau: Dann hilft Ihnen die Lösung aus dem vorliegenden Beitrag weiter.
Datenmodell ändern
Es kann immer mal vorkommen, dass Sie unvorsichtigerweise änderungen am Datenmodell vornehmen. Sie sollten dann anschließend allerdings noch nachvollziehen können, welche änderungen dies waren. Aber wie das im Entwickleralltag so ist, gerät man in einem Programmierrausch und vergisst, die änderungen zu dokumentieren. Schwamm drüber: Wenn sich die Möglichkeit bietet, änderungen im Nachhinein durch einen Vergleich nachvollziehen zu können, kann man sich die Dokumentation doch sparen. Fehlt also nur noch ein geeignetes Tool, um die Datenmodelle zweier Datenbanken abzugleichen. Und dieses programmieren wir in diesem Beitrag.
Vorgehensweise
Es gibt verschiedene Vorgehensweisen für den Vergleich zweier Datenmodelle. Man könnte Tabelle für Tabelle, Feld für Feld und Eigenschaft für Eigenschaft durchlaufen und änderungen herausschreiben. Alternativ schreibt man erstmal den Status Quo der aktuellen und der ursprünglichen Datenbank in Tabellen und vergleicht diese dann. In diesem Beitrag wollen wir die letztere Variante ausprobieren: Nach der Auswahl der Datenbanken sollen deren Informationen gleich in einem Satz von Tabellen landen. Nach dem Einlesen dieser Informationen für die betroffenen Datenbanken durchlaufen wir dann die angefallenen Daten.
Die Anwendung im Einsatz
Bild 1 zeigt das Formular der Lösung zu diesem Beitrag in der Formularansicht. Das Formular besteht aus den folgenden Elementen:
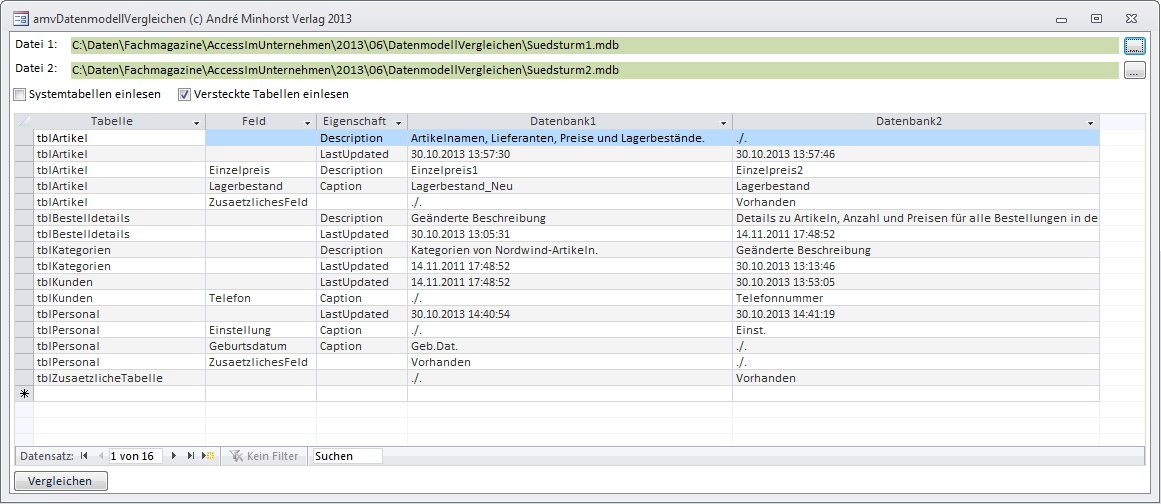
Bild 1: Die Lösung zum Vergleichen von Datenmodellen
- Das Textfeld txtDatei1 zeigt die erste der beiden zu vergleichenden Dateien an.
- Das Textfeld txtDatei2 arbeitet analog zum Textfeld txtDatei1.
- Die Schaltflächen cmdDatei1 und cmdDatei2 rufen einen Datei öffnen-Dialog aus und tragen den Pfad zur ausgewählten Datei in die beiden Textfelder ein. Beide Schaltflächen stellen nicht nur den Pfad in den Textfeldern ein, sondern lesen gleichzeitig auch bereits die Tabellen, Felder, Tabelleneigenschaften und Feldeigenschaften der ausgewählten Datenbank ein.
- Mit dem Kontrollkästchen ctlSystemtabellen legt der Benutzer fest, ob Systemtabellen beim Einlesen berücksichtigt werden sollen.
- Mit dem Kontrollkästchen ctlVersteckteTabellen legt der Benutzer fest, ob als versteckt markierte Tabellen eingelesen werden sollen.
- Das Unterformular zeigt die Unterschiede zwischen den beiden Datenmodellen an.
- Die Schaltfläche cmdVergleich startet den Vergleich der beiden Datenmodelle und zeigt das Ergebnis im Unterformular an.
Datenmodell der Lösung
Das Datenmodell ist hierarchisch aufgebaut. Die oberste Ebene nimmt die die Tabelle tblDatenbanken ein, die aus den beiden Feldern DatenbankID und Datenbank besteht, wobei Datenbank-ID den Part des Primärschlüsselfeldes übernimmt (s. Bild 2).
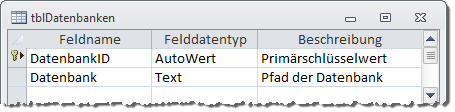
Bild 2: Entwurf der Tabelle tblDatenbanken
Die Tabelle tblTabellen nimmt alle Tabellen der beiden beteiligten Datenbanken auf. Dazu stellt sie die Felder TabelleID als Primärschlüsselfeld, Tabelle mit dem Tabellennamen sowie Systemtabelle und VersteckteTabelle als Ja/Nein-Felder, die anzeigen, ob die Tabelle eine Systemtabelle oder eine versteckte Tabelle ist, zur Verfügung. Außerdem referenziert sie über das Fremdschlüsselfeld Datenbank-ID die Tabelle tblDatenbanken und legt somit fest, zu welcher Datenbank die Tabelle gehört (s. Bild 3).
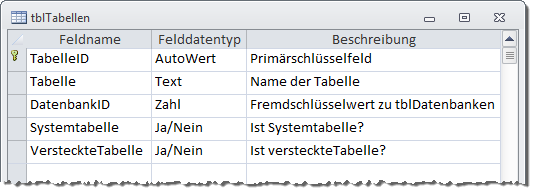
Bild 3: Entwurf der Tabelle tblTabellen
Die einzelnen Felder einer jeden Tabelle speichert die Anwendung in der Tabelle tblFelder (s. Bild 4). Neben dem Primärschlüsselfeld FeldID und dem Feld Feld zum Speichern des Feldnamens enthält auch diese Tabelle wieder ein Fremdschlüsselfeld zum Herstellen der übergeordneten Beziehung, in diesem Fall zur Tabelle tblTabellen.
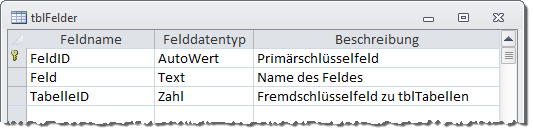
Bild 4: Entwurf der Tabelle tblFelder
Nun fehlen noch die Eigenschaften der Tabelle sowie der einzelnen Felder. Diese speichert die Anwendung in zwei weiteren Tabellen. Die Tabelle tblTabelleneigenschaften speichert alle Eigenschaften der mit dem Fremdschlüsselfeld TabelleID referenzierten Tabelle aus tblTabellen, die Tabelle tblFeldeigenschaften erledigt das Gleiche für die Felder. Dabei enthält die Tabelle tblTabelleneigenschaften neben dem Primär- und dem Fremdschlüsselfeld noch zwei Felder namens Tabelleneigenschaft und Eigenschaftswert (s. Bild 5).
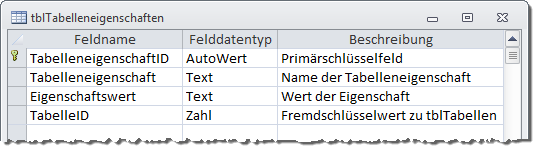
Bild 5: Entwurf der Tabelle tblTabelleneigenschaften
In der Tabelle tblFeldeigenschaften heißen die entsprechenden Felder Feldeigenschaft und Eigenschaftswert (s. Bild 6).
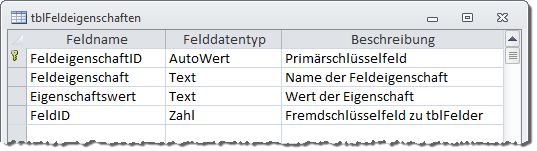
Bild 6: Entwurf der Tabelle tblFeldeigenschaften
Referenzielle Integrität mit Löschweitergabe
Im überblick sieht das Datenmodell wie in Bild 7 aus. Wichtig ist an dieser Stelle, dass wir für alle Beziehungen zwischen den Tabellen referenzielle Integrität mit Löschweitergabe definiert haben. Wenn die nachfolgenden Routinen dann einen Datensatz der Tabelle tblDatenbanken löschen, um die Daten zu dieser Datenbank erneut einzulesen, entfernt Access automatisch auch die Daten aller damit verknüpften Tabellen.
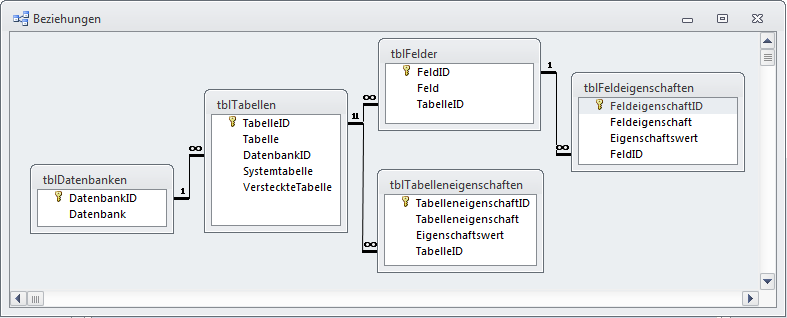
Bild 7: Datenmodell der Anwendung in der übersicht
Optionen speichern
Das Formular ist an die Tabelle tblOptionen gebunden. Diese enthält Felder wie Datei1, Datei2, SystemtabellenEinlesen und VersteckteTabellenEinlesen. Die Textfelder txtDatei1 und txtDatei2 sowie die Kontrollkästchen chkSystemtabellen und chkVersteckteTabellen sind an diese Felder gebunden. Auf diese Weise merkt sich die Lösung die zuletzt verwendeten Einstellungen, was gerade beim Entwickeln einer solchen Lösung praktisch ist.
Datenmodell einlesen
Nachdem die Tabellen zum Erfassen der Elemente des Datenmodells, also Datenbanken, Tabellen, Felder, Tabelleneigenschaften und Feldeigenschaften, erstellt sind, können wir uns an die Füllung derselben begeben. Dies geht mit der Vorstellung einiger Details des Formulars frmDatenmodellVergleichen einher, das im Entwurf wie in Bild 8 aussieht.
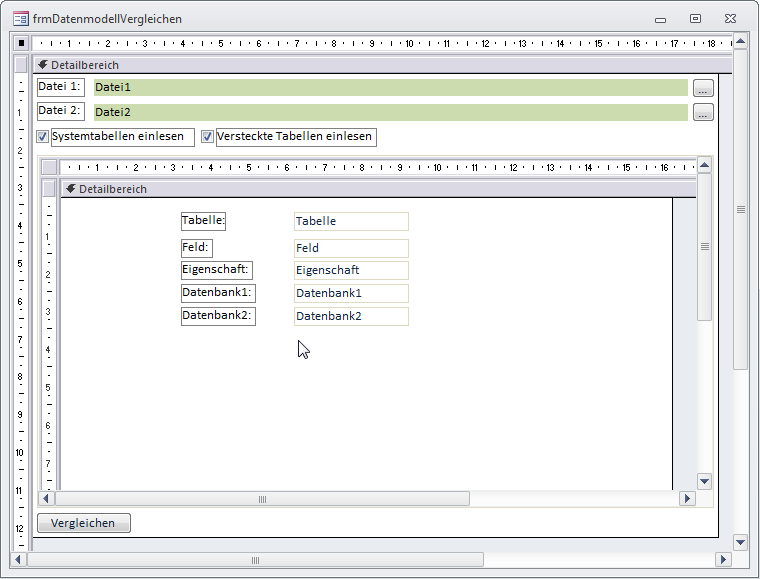
Bild 8: Das Formular frmDatenmodellVergleichen in der Entwurfsansicht
Die Schaltfläche cmdDatei1 ruft beim Anklicken die Prozedur aus Listing 1 auf. Diese Prozedur verwendet die Funktion OpenFileName, die Sie im Modul mdlTools der Datenbank finden, um einen Datei öffnen-Dialog anzuzeigen, mit dem der Benutzer die erste der beiden zu vergleichenden Datenbanken auswählt. Wenn der Benutzer im Dialog die Abbrechen-Taste betätigt, wird Me!txtDatei geleert. Die anschließende Auswertung des Inhalts von txtDatei1 mit der Dir-Funktion und der Vergleich der Länge der ermittelten Zeichenkette liefert nur den Wert True, wenn es sich um eine gültige Datei handelt. Nur in diesem Fall ruft die Prozedur dann die Routine DatenbankEinlesen mit dem Pfad zur Datei als Parameter auf.
Die zweite Schaltfläche cmdDatei2 arbeitet fast genauso – der einzige Unterschied ist, dass sie das Textfeld txtDatei2 füllt.
Datenbank einlesen
Die Routine DatenbankEinlesen, die den Pfad zur einzulesenden Datenbank als Parameter erwartet, aktiviert zunächst die Sanduhr, da der Vorgang bereits für kleinere Datenmodelle ein paar Sekunden dauern kann (in aktuellen System erscheint natürlich längst keine Sanduhr mehr – aber Sie wissen ja, was gemeint ist). Die Prozedur deklariert zwei Database-Variablen: db referenziert die aktuelle Datenbank, um mit der Execute-Methode Datensätze zur Tabelle zum Speichern der Unterschiede hinzufügen zu können, dbQuelle referenziert die zu untersuchende Datenbank.
Diese Datenbank öffnet die Prozedur mit der OpenDatabase-Methode. Sie übergibt dieser Methode den Pfad zur Datenbank sowie den Wert True für den Parameter ReadOnly. Dann löscht sie alle Datensätze aus der Tabelle tblDatenbanken, deren Feld Datenbank den Pfad der hinzuzufügenden Datenbank enthält.
Anschließend legt sie gleich einen entsprechenden neuen Datensatz in der Tabelle tblDatenbanken an und ermittelt mit der Abfrage SELECT @@IDENTITY den Primärschlüsselwert des neu hinzufügten Datensatzes. Dieser wird später zum Anlegen der Datensätze in der verknüpften Tabelle tblTabellen benötigt. Der Aufruf der Routine TabellenEinlesen startet das Einlesen der Tabellen der soeben geöffneten Datenbank. Ist dieser Vorgang, der alle weiteren Aktionen anstößt, abgeschlossen, lässt die Prozedur die Sanduhr wieder verschwinden.
Tabellen einlesen
Die Prozedur TabellenEinlesen erwartet Verweise auf die beiden betroffenen Datenbanken, also die aktuelle und die zu untersuchende Datenbank, sowie den Primärschlüsselwert des zuvor in der Tabelle tblDatenbanken angelegten Datensatzes (s. Listing 3). Die Prozedur durchläuft in einer Schleife alle Elemente der TableDefs-Auflistung des mit dbQuelle referenzierten Database-Objekts. Dabei stellt sie jeweils zunächst die Variable bolEinlesen auf den Wert True ein und gibt einen Status über den aktuellen Bearbeitungsstand in der Statusleiste aus.
Wenn Systemtabellen ignoriert werden sollen, die aktuell mit tdf referenzierte Tabelle aber eine Systemtabelle ist, wird bolEinlesen auf False eingestellt – das geschieht ähnlich für versteckte Tabellen. Ob es sich um eine Systemtabelle oder um eine versteckte Tabelle handelt, erfahren wir durch einen Vergleich des Wertes der Eigenschaft Attributes der Tabelle mit dem Wert der Konstanten dbSystemobject beziehungsweise dbHiddenObject. Hat bolEinlesen anschließend noch den Wert True, fügt die Prozedur der Tabelle tblTabellen einen entsprechenden Datensatz hinzu und speichert den Wert des Primärschlüsselfeldes des neuen Datensatzes in der Variablen lngTabelleID. Anschließend ruft sie die beiden Prozeduren FelderEinlesen und TabelleneigenschaftenEinlesen auf.
Felder einlesen
Die erste der beiden genannten Prozeduren erwartet wiederum zwei Objektvariablen. Dabei handelt es sich wiederum um den Verweis auf die aktuelle Datenbank.
Die Quelldatenbank ist diesmal nicht gefragt, denn wir benötigen ja Zugriff auf die Felder der übergeordneten Tabelle. Daher übergeben wir mit tdf einen Verweis auf das entsprechende TableDef-Objekt und außerdem den Primärschlüsselwert des zuvor angelegten Datensatzes der Tabelle tblTabellen.
Die Prozedur FelderAnlegen durchläuft schlicht über die Variable fld die Fields-Auflistung des TableDef-Objekts tdf. Dabei aktualisiert sie wiederum die Statuszeile von Access, trägt einen entsprechenden Datensatz in die Tabelle tblFelder ein, ermittelt den Primärschlüsselwert des neuen Datensatzes und ruft dann die Prozedur auf, die sich um das Speichern der Eigenschaften der Felder kümmert (s. Listing 4).
Feldeigenschaften einlesen
Die Prozedur FeldeigenschaftenEinlesen wird nun für jedes Feld einmal aufgerufen.
Damit wir in der Statusmeldung einen Ausdruck der Form Tabelle
Die Prozedur durchläuft alle Elemente der Properties-Auflistung des Field-Objekts. Diesmal sollen ja nicht nur Namen gespeichert werden – wie bei der Datenbank, den Tabellen und den Feldern, – sondern die Bezeichnungen der Eigenschaften sowie die entsprechenden Werte. Bei den Eigenschaften des Field-Objekts gibt es die folgende Besonderheit: Das Field-Objekt kommt gleich an mehreren Stellen im DAO-Objektmodell vor. Allerdings werden nicht alle Eigenschaften des Field-Objekts, die über die Properties-Auflistung verfügbar sind, in jedem Kontext genutzt.
So fallen etwa beim Field-Objekt der Fields-Auflistung einer Tabelle die Eigenschaften FieldSize, ForeignName, OriginalValue, ValidateOnSet, Value und VisibleValue unter den Tisch. Und nicht nur das: Wenn Sie versuchen, auf diese Eigenschaften über die Properties-Auflistung zuzugreifen, löst dies einen Fehler aus. Also prüfen wir vorab den Namen des aktuellen Elements der Properties-Auflistung in einer Select Case-Bedingung und ignorieren so die oben genannten Elemente.
Schließlich schreibt die Prozedur für jede Eigenschaft des Tabellenfeldes einen neuen Datensatz in die Tabelle tblFeldeigenschaften. Den neuen Primärschlüsselwert müssen wir uns nicht mehr merken, denn es gibt keine untergeordneten Elemente mehr.
Tabelleneigenschaften einlesen
Fehlt nur noch eine Art von Information: Die Eigenschaften der Tabellen selbst. Diese ermittelt die Prozedur TabelleneigenschaftenEinlesen aus Listing 6. Diese durchläuft wiederum alle Property-Elemente der Properties-Aufistung des TableDef-Objekts.
Hier gibt es eine Besonderheit: Es kann nämlich vorkommen, dass Eigenschaften wie NameMap den Datentyp dbLongBinary aufweisen, deren Inhalt sich nicht so einfach in ein Textfeld schreiben lässt. Deshalb ignoriert die Prozedur nach einer Prüfung auf prp.Type = dbLongBinary gleich komplett.
Die Namen und Werte der Eigenschaften landen dann per INSERT INTO-Aktionsabfrage wie gewohnt in der Zieltabelle, in diesem Fall tblTabelleneigenschaften.
Datenmodell vergleichen
Um die durch die nachfolgend beschriebenen Prozeduren ermittelten Unterschiede zwischen den Datenmodellen der beiden Datenbanken zu speichern und diese schließlich im Unterformular sfmDatenmodellVergleichen anzuzeigen, müssen diese Informationen selbst in einer Tabelle gespeichert werden.
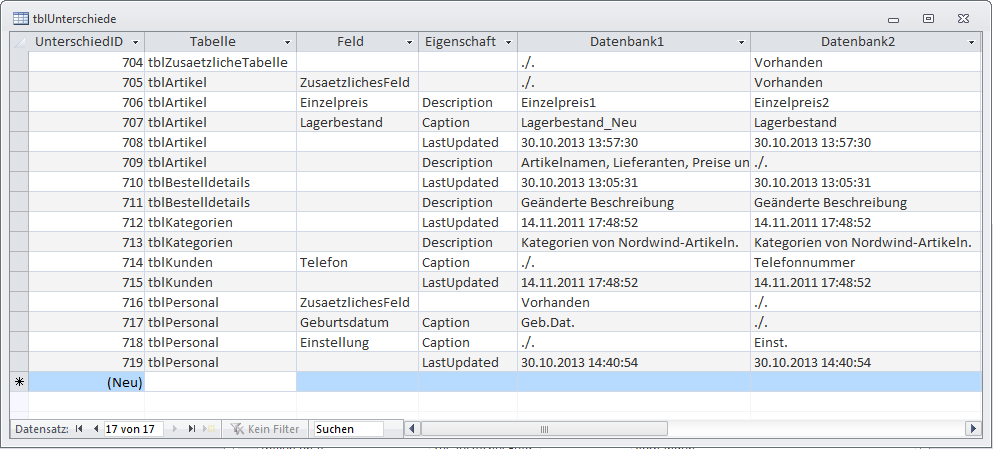
Diese Tabelle heißt tblUnterschiede und sieht im Entwurf wie in Bild 9 aus. Hier ist zu erläutern, dass es verschiedene Arten von Eintragungen geben wird, die Sie auch in Bild 10 wiederfinden: Wenn beispielsweise eine Tabelle in der einen Datenbank enthalten ist, in der anderen jedoch nicht, wird im Feld Tabelle der Tabellenname vermerkt. Je nachdem, ob die Tabelle in Datenbank1 oder in Datenbank2 vorliegt, wird in die entsprechenden Felder entweder der Eintrag Vorhanden oder ./. eingetragen.
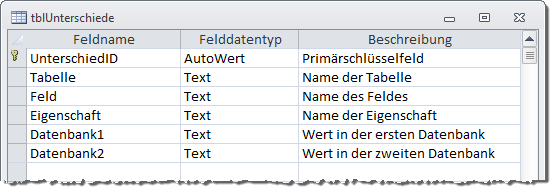
Bild 9: Die Tabelle zum Speichern der Unterschiede zwischen den Datenmodellen
Ende des frei verfügbaren Teil. Wenn Du mehr lesen möchtest, hole Dir ...
Testzugang
eine Woche kostenlosen Zugriff auf diesen und mehr als 1.000 weitere Artikel
diesen und alle anderen Artikel mit dem Jahresabo