
Lies diesen Artikel und viele weitere mit einem kostenlosen, einwöchigen Testzugang.
„Die Drei von der Tankstelle“, „Drei Engel für Charlie“ und „Die drei Fragezeichen“ haben eines gemeinsam: Es sind immer Drei. Drei, von denen jeder seine besonderen Fähigkeiten hat, und Drei, die sich perfekt ergänzen. So ist es auch beim SQL Server. Neben den gespeicherten Prozeduren und Triggern bietet der SQL Server mit den benutzerdefinierten Funktionen eine dritte Komponente, mit der Programmlogik gespeichert und wiederverwendet werden kann. Und weil aller guten Dinge nun mal drei sind, gibt es die benutzerdefinierten Funktionen auch gleich in drei verschiedenen Typen.
Diese drei verschiedenen Typen heißen Inlinefunktionen, Tabellenfunktionen und Skalarfunktionen.
Skalarfunktionen sind weitestgehend mit VBA-Funktionen in Access vergleichbar. Anhand einer optionalen Parameterübergabe wird ein Wert ermittelt und zurückgegeben. Die Inline- und Tabellenfunktionen gehen dort noch einen Schritt weiter, denn sie liefern nicht nur einen Wert, sondern komplette Ergebnismengen.
Die ähnlichkeit zu VBA-Funktionen liegt aber nicht nur in der Ermittlung der Daten, sondern auch in ihrer Anwendung. Gerade die Verwendung eigener geschriebener Funktionen in SELECT-Anweisungen, Access-Abfragen, Gültigkeitsregeln und Modulen ist einer der Vorteile von Access. Dieser Vorteil gilt auch für benutzerdefinierte Funktionen, denn diese sind in der SQL Server-Entwicklung universell einsetzbar. Sie können in SELECT-Anweisungen, in Sichten, in gespeicherten Prozeduren, in Triggern und in anderen benutzerdefinierten Funktionen wie auch in Standardwerten und Einschränkungen verwendet werden und stehen somit für die Realisierung verschiedenster Anforderungen zur Verfügung.
Einsatzmöglichkeiten
Der Grund für den Einsatz von benutzerdefinierten Funktionen ist derselbe wie bei gespeicherten Prozeduren: Die Kapselung von Programmlogik und somit die Kapselung von Geschäftsregeln und von Regeln zur Datenkonsistenz.
Zwar können Sie mit benutzerdefinierten Funktionen keine Daten manipulieren, aber im Vergleich zu gespeicherten Prozeduren sind benutzerdefinierte Funktionen flexibler einsetzbar. Im Gegensatz zu gespeicherten Prozeduren können diese nämlich auch in Sichten, SELECT-Anweisungen oder in anderen benutzerdefinierten Funktionen verwendet werden. Insofern ist der Einsatz benutzerdefinierter Funktionen in manchen Fällen sinnvoller als der Einsatz gespeicherter Prozeduren.
Für die beispielsweise oft benötigte Ermittlung der Produktbezeichnung anhand einer Produktnummer können Sie eine Skalarfunktion erstellen, die immer genau den einen Wert – die Produktbezeichnung – anhand der übergebenen Produktnummer liefert.
Eine andere Skalarfunktion könnte die in der Northwind-Datenbank immer wieder notwendige Summe einer Bestellposition anhand der Spalten Einzelpreis, Menge und Discount berechnen.
Die Werte solcher Skalarfunktionen können Sie als Spalte in einer SELECT-Anweisung, als Filterkriterium in einer WHERE-Bedingung oder in einer INSERT– oder UPDATE-Anweisung verwenden.
In SELECT-Anweisungen und bei Datenmanipulationen stehen auch die Tabellen- und Inlinefunktionen zur Verfügung. Allerdings liefern diese Typen nicht einzelne Werte, sondern Ergebnismengen und sind somit ein guter Ersatz für Sichten oder Tabellen.
Tabellen- und Inlinefunktionen bieten gerade Sichten gegenüber einen großen Vorteil: Sie unterstützen Parameter.
Eine Sicht liefert immer alle Daten der in der Sicht angegebenen SQL-Anweisung. Die Datenermittlung ist starr und kann nicht durch Parameter beeinflusst werden. In Tabellen- und Inlinefunktionen hingegen sind Parameter erlaubt.
Dadurch können die Daten bereits bei der Ermittlung anhand der übergebenen Parameterwerte gefiltert werden.
Es ist schon ein Unterschied, ob in einer Tabellenverknüpfung von Bestellkopf und Bestellpositionen alle Bestellpositionen verknüpft werden oder dabei nur die Bestellpositionen berücksichtigt werden, die dem Wert eines übergebenen Parameters entsprechen.
Sie sehen, die Einsatzmöglichkeiten sind so vielfältig wie die von VBA-Funktionen in Access. Die Verwendung benutzerdefinierter Funktionen ist für Sie insofern eigentlich nichts Neues. Bis auf die Entwicklung dieser Funktionen, denn die schreiben Sie natürlich nicht in VBA, sondern in T-SQL. Dabei sind Art und Umfang der Entwicklungsmöglichkeit abhängig vom jeweiligen Typ.
Inline- und Tabellenfunktionen unterscheiden sich in der Werterückgabe gegenüber den Skalarfunktionen und die Skalar- und Tabellenfunktionen unterscheiden sich anhand der Möglichkeiten zur Ermittlung des Werts beziehungsweise der Werte von den Inlinefunktionen.
Inlinefunktionen
Inlinefunktionen liefern eine Ergebnismenge und können insofern wie Tabellen und Sichten – und somit fast überall – verwendet werden. Aber nur fast, denn bei der Ermittlung von Standardwerten oder der Einhaltung von Gültigkeitsregeln wird dieser Funktionstyp nicht unterstützt.
Der große Vorteil einer Inlinefunktion liegt darin, dass bei der Ermittlung der Daten übergebene Parameterwerte als Filterkriterien verwendet werden können. Damit ist eigentlich auch bereits die Definition einer Inlinefunktion beschrieben. Sie besteht aus einer einzigen SELECT-Anweisung, die anhand eines Parameterwerts gefiltert werden kann. Mehr außer dieser gibt es dort nicht. Von der Programmierung her ist die Inlinefunktion daher die einfachste Variante.
Eine neue Inlinefunktion können Sie mit dem SQL Server Management Studio anlegen. Sie finden die benutzerdefinierten Funktionen unter Programmierbarkeit innerhalb der jeweiligen Datenbank. Dort sehen Sie unter Gespeicherte Prozeduren auch den Knoten Funktionen, der Ihnen nach einem Klick auf den Knoten weitere Verzweigungen anzeigt.
Inlinefunktionen liefern eine Ergebnismenge über eine virtuelle Tabelle und gehören somit zur Gruppe der Tabellenwertfunktionen.
Durch einen Klick mit der rechten Maustaste auf den Knoten Tabellenwertfunktionen können Sie den Befehl Neue Inline-Tabellenwertfunktion (siehe Bild 1) auswählen. Sie erhalten auch hier – wie bei den gespeicherten Prozeduren und Triggern – ein neues Abfragefenster mit einem Vorlageskript.
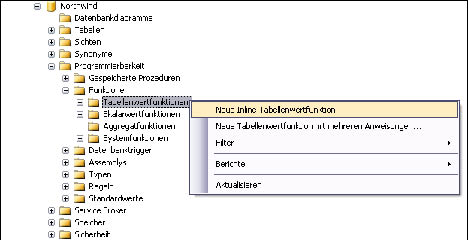
Bild 1: Eine neue Inlinefunktion
Die Definition einer neuen Funktion beginnt mit dem Befehl CREATE FUNCTION, gefolgt vom Funktionsnamen, der immer das entsprechende Schema enthalten muss. Wie bereits bei den gespeicherten Prozeduren beschrieben, werden über das Schema eines Objekts unter anderem die Zugriffsrechte verwaltet. Sofern Sie kein detailliertes Berechtigungskonzept einsetzen, ist das Schema in der Regel dbo. Sie sollten für eine einheitliche Basis für die Weiterentwicklung und eine spätere Konfiguration eines Berechtigungskonzepts immer dbo angeben.
Eine genauere Erklärung der Berechtigungsvergabe anhand der Schemata würde allerdings den Rahmen dieses Artikels sprengen.
Der oder die Parameter, die in der SELECT-Anweisung der Inlinefunktion verwendet werden, geben Sie durch Komma getrennt in Klammern hinter dem Namen der Funktion an. Dabei verwenden Sie das @-Zeichen zur Kennzeichnung jedes einzelnen Parameters sowie den Datentyp.
Nach den Parametern definieren Sie mit RETURNS TABLE, welchen Datentyp das Ergebnis der Funktion aufweist. Eine Inlinefunktion liefert eine Ergebnismenge anhand einer virtuellen Tabelle über den Datentyp TABLE. Die Struktur dieser virtuellen Tabelle ergibt sich aus der SELECT-Anweisung. Nach RETURNS TABLE leiten Sie mit AS den eigentlichen Programmcode ein, der in Klammern angegeben werden muss. Der Programmcode besteht wie bereits erwähnt nur aus einer einzelnen SELECT-Anweisung. Eine weitere Spezifikation zur Kennzeichnung der Tabellenfunktion als Inlinefunktion ist nicht notwendig.
Als Beispiel sehen Sie in Listing 1 die Inlinefunktion dbo.ifArtikelEinerKategorie, die alle aktiven oder inaktiven Artikel einer bestimmten Kategorie als Ergebnismenge liefert.
Listing 1: Beispiel für eine Inlinefunktion
CREATE FUNCTION dbo.ifArtikelEinerKategorie ( @CategoryId int, @Discontinued bit ) RETURNS TABLE AS RETURN ( SELECT dbo.Products.ProductId, dbo.Products.ProductName, dbo.Products.SupplierID, dbo.Suppliers.CompanyName, dbo.Products.CategoryID, dbo.Categories.CategoryName, dbo.Products.QuantityPerUnit, dbo.Products.UnitPrice, dbo.Products.UnitsInStock, dbo.Products.UnitsOnOrder, dbo.Products.ReorderLevel, dbo.Products.Discontinued FROM dbo.Products INNER JOIN dbo.Categories ON dbo.Products.CategoryID = dbo.Categories.CategoryID INNER JOIN dbo.Suppliers ON Products.SupplierID = Suppliers.SupplierID WHERE dbo.Products.CategoryId = @CategoryId AND dbo.Products.Discontinued = @Discontinued )
Die Erklärung dieser Inlinefunktion ist recht einfach. Die SELECT-Anweisung ermittelt alle Artikeldaten zuzüglich der Bezeichnung der Kategorie, zu der die Artikel gehören, sowie den Firmennamen des Lieferanten. Diese Ergebnismenge wird bei der Ermittlung auf eine Kategorie gefiltert, die über den Parameter @CategoryId an die SELECT-Anweisung übergeben wird. Zusätzlich wird über den Parameter @Discontinued bestimmt, ob die Ergebnismenge nur die aktiven Artikel (Wert 0) oder nur die inaktiven Artikel (Wert 1) enthält.
Bei der SELECT-Anweisung müssen Sie darauf achten, dass alle Spalten einen Namen bekommen. Dies gilt insbesondere bei der Verwendung von Konstanten oder berechneten Spalten. Hier muss zwingend ein Alias vergeben werden. Diese Inlinefunktion können Sie nun wie eine „parametrisierte Sicht“ verwenden. Folgender Aufruf liefert alle aktiven Artikel der Kategorie 1:
SELECT * FROM dbo.ifArtikelEinerKategorie (1, 0)
Sie können die Inlinefunktion auch in einer Tabellenverknüpfung verwenden. Die folgende Abfrage etwa liefert alle Bestellpositionen, die inaktive Artikel der Kategorie 1 beinhalten:
SELECT * FROM dbo.[Order Details] OD INNER JOIN dbo.ifArtikelEinerKategorie(1, 1) AEK ON OD.ProductId = AEK.ProductId
Für einfache SELECT-Anweisungen ist die Inlinefunktion die erste Wahl, da sie schnell programmiert und flexibel einsetzbar ist. Flexibel einsetzbar sind auch die Tabellenfunktionen – und sie sind auch flexibel in der Ermittlung der Ergebnismenge.
Tabellenfunktionen
Im Unterschied zu einer Inlinefunktion können in einer Tabellenfunktion mehrere SQL-Anweisungen zur Ermittlung der Ergebnismenge gespeichert werden.
Dies sagt bereits der Kontextmenübefehl des Knotens Tabellenwertfunktionen aus: Neue Tabellenwertfunktion mit mehreren Anweisungen (siehe Bild 1). Auch dieser Befehl liefert Ihnen eine Skriptvorlage in einem neuen Abfragefenster. Diese unterscheidet sich in einigen Punkten von der der Inlinefunktion.
Bei einer Tabellenfunktion wird die Struktur der virtuellen Tabelle nicht anhand einer SELECT-Anweisung bestimmt, sondern muss durch eine TABLE-Variable explizit definiert werden. Insofern gibt es hier kein RETURNS TABLE, sondern ein RETURNS gefolgt von der Definition der TABLE-Variablen.
Die einzelnen SQL-Anweisungen zur Ermittlung der Ergebnismenge werden in einer Tabellenfunktion im BEGIN…END-Block zusammengefasst. Mit diesen SQL-Anweisungen ermitteln Sie nach und nach die Daten und füllen mit diesen die TABLE-Variable. Dabei stehen Ihnen alle Möglichkeiten der T-SQL-Programmierung zur Verfügung, bis auf wenige Ausnahmen:
- Ausgabe von Meldungen: Benutzerdefinierte Funktionen liefern immer Werte oder Ergebnismengen. Meldungen, die zum Beispiel auf einen Fehler hinweisen und durch RAISERROR oder PRINT ausgelöst werden, werden nicht unterstützt.
- Datenmanipulationen außerhalb der Funktion: Innerhalb der Tabellenfunktion können Sie die Daten der dort enthaltenen Objekte – sprich temporären Tabellen oder Table-Variablen – manipulieren; die Daten anderer Tabellen jedoch nicht.
- Verwendung von gespeicherten Prozeduren: Gespeicherte Prozeduren können in benutzerdefinierten Funktionen nicht aufgerufen werden. Der Befehl EXECUTE wird nicht unterstützt. Dies würde auch der gerade erwähnten Einschränkung widersprechen, dass in benutzerdefinierten Funktionen keine Daten von Tabellen manipuliert werden können. Wären in benutzerdefinierten Funktionen gespeicherte Prozeduren erlaubt, wären über diese die Datenmanipulationen möglich.
Die Programmlogik wird wie bei gespeicherten Prozeduren durch den Befehl RETURN beendet und dadurch die ermittelte Ergebnismenge an die aufrufende Instanz geliefert.
In Listing 2 sehen Sie die Tabellenfunktion dbo.tfMitarbeiterHierarchie, die die Hierarchie der Mitarbeiter im Unternehmen auflistet. Als Ergänzung wird pro Mitarbeiter das Alter hinzugefügt.
Listing 2: Beispiel für eine Tabellenfunktion
CREATE FUNCTION dbo.tfMitarbeiterHierarchie () RETURNS @Mitarbeiter TABLE ( HierarchieEbene int, ManagerId int, MitarbeiterId int, Titel nvarchar(30), Mitarbeiter nvarchar(30), [Alter] int ) AS BEGIN -- Hierarchie per CTE ermitteln WITH cteHierarchie (Ebene, MgrId, EmpId, Titel, Mitarbeiter) AS ( SELECT 1, E.ReportsTo, E.EmployeeId, E.Title, E.LastName + €š, €š + E.FirstName FROM dbo.Employees As E WHERE ReportsTo Is Null UNION ALL SELECT Ebene+1, E.ReportsTo, E.EmployeeId, E.Title, E.LastName + €š, €š + E.FirstName FROM dbo.Employees As E INNER JOIN cteHierarchie ON cteHierarchie.EmpId = E.ReportsTo ) INSERT INTO @Mitarbeiter (HierarchieEbene, ManagerId, MitarbeiterId, Titel, Mitarbeiter) SELECT * FROM cteHierarchie ORDER BY Ebene, MgrId; -- Alter ergänzen UPDATE @Mitarbeiter SET [Alter] = CASE WHEN DateAdd(Year, Datediff(Year, BirthDate, getdate()), BirthDate) > getdate() THEN Datediff(Year, BirthDate, getdate()) - 1 ELSE DateDiff(Year, BirthDate, getdate()) END FROM @Mitarbeiter As Mitarbeiter INNER JOIN dbo.Employees ON Mitarbeiter.MitarbeiterId = dbo.Employees.EmployeeId RETURN END
Der Quellcode dieser Tabellenfunktion sieht auf den ersten Blick kompliziert aus, aber auf den zweiten Blick ist zu erkennen, dass hier lediglich Daten ermittelt und in die Rückgabe-Tabelle geschrieben werden, um danach noch per Update ergänzt zu werden. Doch der Reihe nach:
Am Anfang, noch vor dem einleitenden AS, steht die Definition der TABLE-Variablen, über die die Ergebnismenge zurückgeliefert wird. Die Definition einer TABLE-Variablen ist identisch mit der des T-SQL-Befehls CREATE TABLE. Innerhalb des BEGIN…END-Blocks wird die TABLE-Variable mit Daten gefüllt. Dabei wird die Hierarchie der Mitarbeiter über eine rekursive CTE ermittelt und per INSERT-Anweisung in die TABLE-Variable geschrieben. CTE – die Common Table Expression – gibt es seit SQL Server 2005.
Anschließend müssen die Datensätze in der TABLE-Variablen noch um das Alter des jeweiligen Mitarbeiters ergänzt werden. Die Berechnung des Alters erfolgt pro Mitarbeiter in einer UPDATE-Anweisung. Mittels RETURN wird die benutzerdefinierte Funktion beendet und die Ergebnismenge an die aufrufende Instanz übermittelt.
Die in diesem Beispiel erstellte Tabellenfunktion benötigt keine Parameter. Beim Aufrufen der Funktion müssen trotzdem die Klammern mit angegeben werden, da sonst die Funktion nicht erkannt wird.
Die folgende Abfrage liefert die Hierarchie der Mitarbeiter inklusive des Alters des jeweiligen Mitarbeiters:
SELECT * FROM tfMitarbeiterHierarchie()
Sie sehen, in einer Tabellenfunktion kann einiges an Logik zur Ermittlung der Ergebnismenge implementiert werden. Dies gilt auch für die Ermittlung von nur einem Wert – und dafür gibt es die Skalarfunktionen.
Skalarfunktion
Skalar Was ist nochmal ein Skalar Nun, wozu gibt es Wikipedia: „Eine skalare Variable ist im Kontext von Programmiersprachen eine Variable, die einen einzelnen Wert speichert.“ Also eine doch durchaus treffende Bezeichnung für eine benutzerdefinierte Funktion, die als Ergebnis nur einen einzelnen Wert liefert.
Die Ermittlung eines solchen Werts kann ein einzelnes SELECT-Statement, eine Konstante oder auch mehrere Zeilen Code wie bei der Tabellenfunktion sein. Art und Umfang zur Ermittlung dieses einzelnen Wertes ist Ihnen überlassen. Bei der Programmierung haben Sie dieselben Möglichkeiten, aber auch dieselben Einschränkungen, wie bei den Tabellenfunktionen.
Skalarfunktionen werden gerne als „gekapselte Konstanten“ verwendet, da hier lediglich eine Konstante zurückgegeben wird. Sollte sich diese Konstante mal ändern, muss sie nur an einer Stelle – in der Skalarfunktion – geändert werden.
Die Einsatzmöglichkeiten von Skalarfunktionen sind sehr vielfältig. Sie können als Spalten in einer SELECT-Anweisung, in WHERE-Bedingungen oder auch als Initialisierung von Variablen in T-SQL verwendet werden, wie auch in gespeicherten Prozeduren, Sichten, Triggern und in anderen benutzerdefinierten Funktionen.
Auch in Einschränkungen und Standardwerten einer Tabelle können Skalarfunktionen genutzt werden. Bevor Sie also einen Trigger für etwas ausgefallenere Standardwerte beziehungsweise Einschränkungen verwenden, sollten Sie zunächst den Einsatz einer Skalarfunktion prüfen.
Um eine neue Skalarfunktion zu erstellen, müssen Sie im Knoten Funktionen aus dem Kontextmenü des Knotens Skalarwertfunktionen den Eintrag Neue Skalarwertfunktion anklicken. Sie erhalten auch hier wieder eine neue Abfrage mit einem Vorlageskript.
Die Struktur ähnelt der einer Tabellenfunktion. Auch hier definieren Sie mit der Anweisung RETURNS den Datentyp des Rückgabewerts. Nur, dass es sich hier nicht um eine Definition einer virtuellen Tabelle, sondern um einen Datentyp für einen einzelnen Wert handelt. Dabei können Sie alle Datentypen nutzen, die der SQL Server im Bereich einer Tabellendefinition zur Verfügung stellt, mit Ausnahme der Datentypen text, ntext, image oder timestamp. Es gibt noch einen weiteren Datentyp, den Sie nicht verwenden können. Dieser steht aber auch nicht als Datentyp für Tabellen zur Verfügung, sondern nur innerhalb der T-SQL-Programmierung: der Datentyp TABLE. So leicht ist der SQL Server nun auch wieder nicht auszutricksen.
In einer Skalarfunktion entwickeln Sie die Logik wie auch bei der Tabellenfunktion innerhalb eines BEGIN…END-Blocks. Den ermittelten Wert übergeben Sie dann am Ende mit dem Befehl RETURN. Bei einer Skalarfunktion muss die Variable, die den ermittelten Wert enthält, zwingend hinter der Anweisung RETURN angegeben werden.
Im folgenden Beispiel wird eine bereits eingangs erwähnte Anforderung umgesetzt: In einer Skalarfunktion soll die Produktbezeichnung anhand der übergebenen Produkt-ID ermittelt werden. Die Umsetzung dieser Anforderung sehen Sie in Listing 3.
Listing 3: Eine Skalarfunktion zur Ermittlung von Produktbezeichnungen
CREATE FUNCTION dbo.sfProduktBezeichnung ( @ProductId int ) RETURNS nvarchar(40) AS BEGIN DECLARE @ProductName nvarchar(40) SELECT @ProductName = ProductName FROM Products WHERE ProductId = @ProductId RETURN @ProductName END
Mit dieser Skalarfunktion können Sie nun in SELECT-Anweisungen anhand der Produkt-ID die Bezeichnung ohne aufwendige Tabellenverknüpfungen ausgeben. In Bild 2 sehen Sie eine solche Anweisung einschließlich des Ergebnisses.
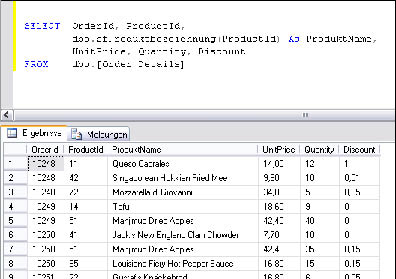
Bild 2: Eine Skalarfunktion im Einsatz
Ende des frei verfügbaren Teil. Wenn Du mehr lesen möchtest, hole Dir ...
Testzugang
eine Woche kostenlosen Zugriff auf diesen und mehr als 1.000 weitere Artikel
diesen und alle anderen Artikel mit dem Jahresabo