
Lies diesen Artikel und viele weitere mit einem kostenlosen, einwöchigen Testzugang.
Es ist eine immer wiederkehrende Aufgabenstellung: Daten werden als Excel-Datei geliefert und sollen in eine Datenbank eingelesen werden. Viele Access-Entwickler verwenden hier gerne die Methode DoCmd.TransferSpreadsheet. Diese stößt allerdings schnell an ihre Grenzen. Dieser Beitrag zeigt, welche Möglichkeiten es jenseits dieser Grenzen gibt – insbesondere dann, wenn die Importdaten im weit verbreiteten Kraut-und-Rüben-Format vorliegen.
Die TransferSpreadsheet-Methode weist im Wesentlichen zwei Einschränkungen auf: Sie steht nur innerhalb von Access-Anwendungen zur Verfügung – wenn Sie eine Anwendung als VB-Projekt entwerfen oder dorthin migrieren möchten, müssen Sie die Sache selbst in die Hand nehmen – und es ist begrenzt auf einzulesende Daten, die bereits ein relationales Format aufweisen, die also so vorliegen, wie sie auch in der Datenbank erscheinen sollen. Diese zweite Einschränkung betrifft auch andere Methoden, wie zum Beispiel den SQL-Zugriff auf Excel über den ISAM-Treiber oder das direkte Abfragen einer Excel-Datei über ein DAO- oder ADODB-Recordset.
Beim Verarbeiten der Importdaten spielen die Modulo- und Integerdivision eine entscheidende Rolle. Falls Sie mit diesen Operatoren nicht gut vertraut sind, finden Sie im folgenden Teil eine kleine Erläuterung. Wenn Sie auf diesem Gebiet jedoch firm sind, können Sie auch direkt zur ersten Aufgabenstellung springen.
Kleine Einführung: Ganzzahldivision
Die Modulo- (Mod) und Integer-Division (\) sind Ganzzahloperationen, die Folgendes leisten:
- a \ b ergibt die größte ganze Zahl, die multipliziert mit b kleiner oder gleich a ist.
- a Mod b ergibt den Rest dieser Division.
Einige Beispiele:
5 \ 2 = 2 5 Mod 2 = 1 14 \ 5 = 2 14 Mod 5 = 4
Das ist Division der zweiten Grundschulklasse: zwei passt zweimal in fünf, Rest eins; fünf passt zweimal in 14, Rest vier. Was Sie damit anfangen können, zeigt sich aber viel anschaulicher anhand einer kleinen Schleife:
For i = 0 To 15 Debug.Print i \ 5; i Mod 5 Next i
Für \ ergibt sich die Zahlenreihe 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 3, für Mod 0, 1, 2, 3, 4, 0, 1, 2, 3, 4, 0, 1, 2, 3, 4, 0. Mit der Basis 3 statt 5 ergäbe sich für \ die Reihe 0, 0, 0, 1, 1, 1, 2, 2, 2, 3, 3, 3 … und für Mod 0, 1, 2, 0, 1, 2, 0, 1, 2 …
Schauen Sie sich nun die Indexpaare eines Arrays aus Tabelle 1 an. Wenn Sie die Zellen zeilenweise durchnumerieren, lauten die Zeilenindizes (1, 1, 1, 2, 2, 2, 3, 3, 3) und die Spaltenindizes (1, 2, 3, 1, 2, 3, 1, 2, 3). Das sind genau die um eins erhöhten Ergebnisse von Zellennummer \ 3 und Zellennummer Mod 3.
|
Tab. 1: Feldindizes einer Tabelle |
||
Durch Verschiebung und überlagerung solcher Indexfolgen durch Multiplikation, Addition und mehrfacher Integerdivision mit verschiedenen Basen können Sie aus einem laufenden Zähler beliebige Indexpaare erzeugen, mit denen Sie die Reihenfolge zum Schreiben der Daten aus einem Array in Felder und Datensätze festlegen – Beispiele dazu folgen.
Beispiel 1: Daten aus Kreuztabellen einlesen
Viel öfter als ordentlich angeordnete Daten mit Spalten für Felder und Zeilen für Datensätze liefern Kunden ein datentechnisches Tohuwabohu, das Sie nur per Excel-Automation umsetzen können (siehe Bild 1).
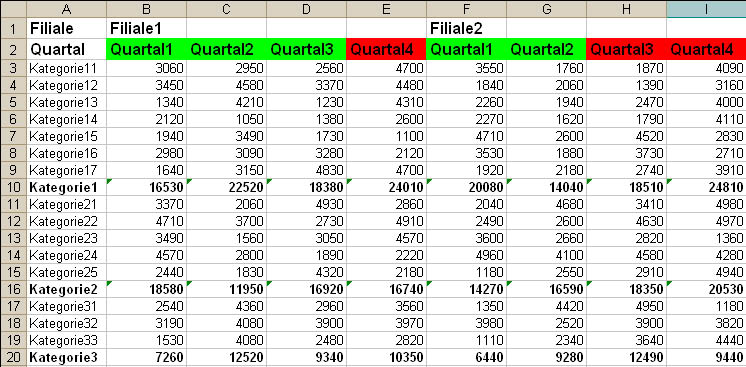
Bild 1: So sehen die zu importierenden Daten aus.
Die Daten sollen die Entwicklung der Quartalsumsätze in verschiedenen Kategorien (Konten, Vertriebsbereiche) von mehreren Filialen darstellen. Die eigentlichen Kategorien (Kategorie##) sind noch einmal Oberkategorien (Kategorie#) untergeordnet, die jeweils die Summe der untergeordneten Kategorien darstellen.
Sie konnten dem Kunden folgende Zusicherungen abringen:
- In Zeile 1 stehen immer die Filialnamen. Für jede Filiale werden immer Zahlen für alle vier Quartale geliefert. Zwischen je zwei Filialnamen sind also sicher drei Leerzellen.
- In Zeile 2 stehen die Quartalsbezeichnungen. Diese sind nicht fix, sondern können ohne Vorankündigung auch 1Q, 1.Quartal, Q1, Quartal eins et cetera lauten. Die Importroutine soll das klaglos verdauen und in der DB in jedem Fall die Zahlen 1, 2, 3 und 4 fürs Quartal ausgeben.
Bekannte Zahlen für abgelaufene Quartale, die je Filiale bereits vollständig verarbeitet wurden, sind durch einen grünen Hintergrund in der Quartalsbezeichnung gekennzeichnet. Für in der Zukunft liegende beziehungsweise noch nicht verarbeitete Quartale werden dennoch Zahlen geliefert; es handelt sich um extrapolierte Schätzungen der Controlling-Abteilung. Solche Werte sind an einem roten Hintergrund erkennbar. In der Datenbank sollen die Werte durch Flags wie Gemessen oder Geschätzt gekennzeichnet werden.
Spalte A enthält die Kategorienamen. Oberkategorien werden als berechnete Werte nicht in die Datenbank übernommen. Oberkategorien sind an Fettschrift erkennbar.
Das Zielformat in der Datenbank sieht also aus wie in Bild 2 – hier dargestellt unter Excel.
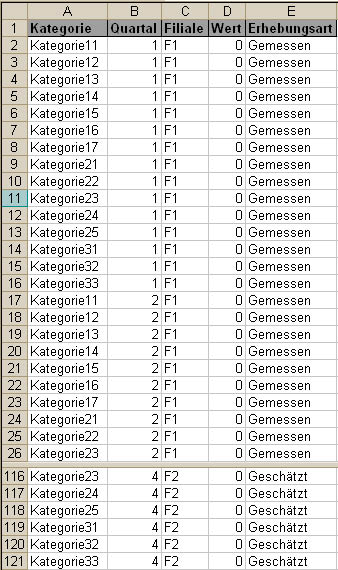
Bild 2: Zielformat der Tabelle aus Bild 1
Diese Aufgabe ist in keiner Weise mit TransferSpreadsheet oder anderen relationalen Methoden lösbar, zumal einige der abzubildenden Informationen in Form von Zellformatierungen geliefert werden.
Um die Tabelle im Beispiel zu verarbeiten, ist zunächst ein wenig Kenntnis der Objekthierarchie von Excel nötig.
Zuoberst steht das Application-Objekt, das die Anwendung darstellt. Darunter findet sich ein WorkBook-Objekt – das ist die zu verarbeitende Excel-Mappe. In dieser wiederum müssen Sie das Tabellenblatt, das die Daten enthält, identifizieren, was mit einem WorkSheet-Objekt geschieht. Hier sind jetzt noch der genaue Zellbereich beziehungsweise die einzelnen Zellen, welche die Daten liefern, zu identifizieren. Letzteres geschieht durch ein Range-Objekt. Die Hierarchie sieht also wie folgt aus:
Application
Workbooks("Mappename")
WorkSheets("Blattname")
Range(<Zellbereich>)
Importieren mit der Cells-Eigenschaft
Nachfolgend sehen Sie zunächst die benötigten Deklarationen (den kompletten Code finden Sie im Modul ImportPivot der Beispieldatenbank, die importierte Tabelle heißt Pivot und ist in der Excel-Datei Daten.xls zu finden). Wenn Sie hier das Application-Objekt vermissen: Da beim Import keine visuelle Interaktion des Benutzers mit der einzulesenden Excel-Datei erforderlich ist, wird Ihnen hier ein Verfahren vorgestellt, das mit einem Minimum an Code alle Vorgänge komplett im Hintergrund ausführt.
Dim xlWbk As Excel.Workbook Dim xlSht As Excel.Worksheet Dim xlRng As Excel.Range Dim Path As String Dim LastCol As Long Dim LastRow As Long Dim c As Long, r As Long Dim rcs As DAO.Recordset
Zunächst müssen Sie natürlich den Pfad der einzulesenden Datei bekannt geben, was je nach Anforderung relativ zur Programmdatei mit einem festen Pfad oder einem Datei-öffnen-Dialog geschehen kann. Damit können Sie direkt und ohne Umstände ein Workbook-Objekt, das die Mappe darstellt, erzeugen. Davon leiten Sie ein Worksheet-Objekt zur Darstellung des Tabellenblatts mit den Daten ab:
Path = "Pfad\Daten.xls"
Set xlWbk = CreateObject(Path)
Set xlSht = _
xlWbk.Worksheets("Pivot")
Die folgenden Anweisungen ermitteln die letzte beschriebene Spalte und Zeile des Datenbereichs, damit Sie bezüglich der Datenmenge völlig flexibel sind. Das dort aufgebaute Recordset identifiziert die Zieltabelle und dient dazu, die Daten dort einzutragen:
LastRow = xlSht.Cells(&H10000, 1).End(xlUp).Row LastCol = xlSht.Cells(2, &H100&).End(xlToLeft).Column
Die eigentliche Arbeit leistet die Schleife aus Listing 1. Die Variable c durchläuft die Spaltenindizes, r die Zeilenindizes. Mit der Cells-Methode des Worksheet-Objekts wird dynamisch jeweils ein Range, der nur eine Zelle enthält, identifiziert. Die Schleife beginnt mit c = 2 und r = 3, also der Zelle B3, weil dort die Nutzdaten anfangen (siehe Bild 2).

Bild 3: Weiteres Beispiel eines Importformats – diesmal ohne durch Formatierungen definierte Informationen
Listing 1: Auslesen von Daten aus einer pivot-artigen Tabelle
Set rcs = CurrentDb.OpenRecordset _
(„SELECT * FROM tblImport WHERE ID Is Null“)
With xlSht
For c = 2 To LastCol
For r = 3 To LastRow
If .Cells(r, 1).Font.Bold = False Then
rcs.AddNew
rcs.Fields(„Kategorie“).Value = .Cells(r, 1).Value
rcs.Fields(„Quartal“).Value = ((c – 2) Mod 4) + 1
rcs.Fields(„Filiale“).Value = _
.Cells(1, 4 * ((c – 2) \ 4) + 2).Value
rcs.Fields(„Wert“).Value = .Cells(r, c).Value
If .Cells(2, c).Interior.Color = 65280 _
Then rcs.Fields(„Erhebungsart“).Value = „Erhoben“
If .Cells(2, c).Interior.Color = 255 _
Then rcs.Fields(„Erhebungsart“).Value = „Geschätzt“
rcs.Update
End If
Next r
Next c
End With
rcs.Close
Set rcs = Nothing
.Cells(r, 1).Font.Bold = False prüft, ob ein echter Wert oder eine Summe vorliegt – Letztere wird Ihnen ja als Fett gekennzeichnet und nicht importiert -, die Kategoriebezeichnung steht als Zeilenkopf immer in Spalte 1, daher .Cells(r, 1).Value.
Der Quartalswert 1 bis 4 wird nicht ausgelesen – Sie wollen von der verwendeten Bezeichnung unabhängig sein -, sondern aus der Spaltennummer berechnet, ausgehend von der ersten Datenspalte und der Regel, dass sich der Wert alle vier Spalten wiederholt: ((c – 2) Mod 4) + 1
Die Filialbezeichnungen stammen aus der ersten Zeile, stehen aber immer nur über dem ersten Quartal. Dem trägt die Formel .Cells(1, 4 x ((c – 2) \ 4) + 2).Value Rechnung.
Richtig einfach haben Sie es mit den Nutzdaten – die Formel lautet: .Cells(r, c).Value
Das Feld Erhebungsart ermitteln Sie aus den Hintergrundfarben, also .Cells(2, c).Interior.Color = 65280 beziehungsweise .Cells(2, c).Interior.Color = 255. Der restliche Code betrifft das Recordset und dürfte selbsterklärend sein.
Diese Methode, bei der mittels Cells(r, c) der Reihe nach die relevanten Zellen identifiziert und darüber sowohl deren Werte als auch Formatierungen gelesen werden können, ist sehr anschaulich und für kleinere Datenmengen völlig ausreichend. Es geht aber auch noch erheblich schneller, wie die folgende fiktive Anforderung zeigt.
Beispiel 2: Daten im Kreuzschema einlesen ohne Formatierungen
Im zweiten Beispiel liegen die Daten zwar immer noch in einem Kreuzschema, aber wenigstens in Textform vor. Dadurch brauchen Sie keine Zellformatierungen mehr auszulesen, sondern müssen nur die Zellinhalte bestimmen. Dadurch können Sie eine Methode einsetzen, die die benötigte Laufzeit um einen Faktor 15 bis 25 (bei vielen Daten noch erheblich mehr) reduziert.
Excel bietet die Möglichkeit, alle Werte eines beliebig großen Zellbereichs einer Variant-Variablen zuzuweisen. Dabei wird automatisch ein zweidimensionales Array erzeugt, das man dann ähnlich wie eben die Tabelle selbst mit einer Schleife durchlaufen kann. Da Arrays auf Grund ihres Speicherdesigns schnelle Strukturen sind, ist ein solcher Durchlauf erheblich zügiger als einer durch die mit der Cells-Eigenschaft immer wieder aufgebaute Objekt-Struktur.
Die Deklarationen dieses Beispiels stimmen im wesentlichen mit denen aus dem ersten Beispiel überein, wir beschreiben daher an dieser Stelle nur die wichtigsten Elemente der Routine – das komplette Listing finden Sie im Modul ImportBlock.
Zunächst belegen Sie eine Range-Variable mit dem einzulesenden Zellbereich. Hier ist Cells(1, 1), also A1, die Startzelle. Statt eine Endzelle anzugeben, vergrößern Sie den Bereich ganz bequem mit der Methode Resize(Zeilen, Spalten) des Range-Objekts auf die erforderliche Größe, was sich ausgehend von (1, 1) mit LastRow und LastCol deckt. Um diesen gesamten Zellbereich auszulesen, genügt der Einzeiler v = xlRng.Value.
Die Excel-Mappe wird nun nicht mehr benötigt und daher mit Close geschlossen. Da zum (unsichtbaren) öffnen der Mappe ein Start von Excel unumgänglich ist, wird es hierbei ganz automatisch wieder geschlossen – ein Segen der impliziten Anwendungsinstanzierung. Durch diese Maßnahme geben Sie je nach Version 20 bis 30 Megabyte Arbeitsspeicher für die laufende Excel-Anwendung frei; im Speicher verbleibt nur ein kompaktes Array, das alle Daten enthält.
Set xlRng = _
xlSht.Cells(1, 1).Resize(LastRow, LastCol) v = xlRng.Value xlWbk.Close xlDoNotSaveChanges
Nach dem üblichen Erstellen eines Recordsets mit der Zieltabelle arbeitet Access die nachfolgend vorgestellte Schleife ab, die nun über das Array läuft. Dieses automatisch generierte Array, das in der Variant-Variablen v enthalten ist, wird von Excel immer einsbasiert und zweidimensional erzeugt, verhält sich also so, als sei es wie folgt deklariert worden:
Dim v(1 To Zeilen, 1 To Spalten)
Daran können Sie nichts ändern und Sie müssen sich im Code darauf einstellen.
For i = 1 To LastRow * LastCol
c = (i - 1) Mod 13 + 1
r = (i - 1) \ 13 + 1
If (c - 1) * (r - 1) > 0 Then
.AddNew
.Fields("BG").Value = v(r, 1)
.Fields("Monat").Value = v(1, c)
.Fields("dtWert").Value = v(r, c)
.Update
End If
Next i
Diese alternative Methode vermeidet eine Doppelschleife. Zunächst durchläuft die Routine die Zellen von (1, 1) bis (LastRow, LastCol), was dem Produkt aus LastRow x LastCol Zellen entspricht. Die benötigten Zeilen- und Spaltenindizes ergeben sich aus der Spaltenzahl – hier sind es insgesamt 13 für zwölf Monate und die Kopfspalte, was aber auch dynamisch aus dem Abstand der ersten Datenspalte und LastCol berechnet werden kann. Wenn sich die Spalten alle 13 Zellen wiederholen und sich entsprechend die Zeilennummer alle 13 Zellen um eins erhöht, bekommen Sie die entsprechenden Indizes mit den folgenden Formeln der Modulo- und Integerdivision:
c = (i - 1) Mod 13 + 1 r = (i - 1) \ 13 + 1
Da die Nutzdaten in der zweiten Zeile und zweiten Spalte beginnen, brauchen Sie eine zusätzliche Prüfung:
If c > 1 And r > 1
Schöner, da nur mit Mathematik auskommend, ist die folgende Variante:
If (c - 1) * (r - 1) > 0
Noch einen obendrauf setzt diese Zeile:
If r * c > r + c - 1
Die Zuweisungen an die Felder des Recordsets sehen so aus:
- Die Buchungsgruppe BG steht immer in der aktuellen Zeile und ersten Spalte, also v(r, 1).
- Der Monat, der natürlich auch eine beliebige andere Kategorie sein könnte, steht immer in der aktuellen Spalte und ersten Zeile, also v(1, c).
- Der jeweilige Nutzwert steht immer in v(r, c).
Der Zeitgewinn der Array-Methode gegenüber der Cells-Methode ist erheblich. Wollten Sie auch das erste Beispiel darauf umstellen, gingen Sie wegen der teilweise als Formatierungen vorliegenden Daten folgendermaßen vor: Bedeutungstragende Formatierungen kommen in der Kopfspalte und zwei Kopfzeilen vor.
Durchlaufen Sie diese Bereiche mit Cells und legen Sie die relevanten Informationen in Hilfs-Arrays ab. Lesen Sie den eigentlichen Datenbereich mit Value in ein Variant-Array ein. Bei großen Datenmengen ist das trotz des höheren Code-Aufwands immer noch schneller, als alles mit Cells durchzugehen.
Angenommen, Sie lesen 50 Spalten á 2.000 Zeilen ein. Mit dem Vorgehen aus dem ersten Beispiel wenden Sie 100.000 Mal Cells an. Mit der hier vorgeschlagenen Kombination wenden Sie 2.050 Mal Cells an und einmal Value.
Noch besser ist es natürlich, Sie reden dem Kunden aus, Formate als Informationsträger zu benutzen, dann wenden Sie in jedem Fall nur einmal Value an.
Immer sollten Sie aber berücksichtigen, wie oft der Import tatsächlich stattfindet – geschieht dies nur einmal, können Sie die Performance natürlich eher vernachlässigen, als wenn regelmäßig Daten importiert werden.
Import aus Tabellen mit redundanten
Informationen
Der Import soll jetzt noch etwas schwieriger werden. Ausgehend vom vorherigen Beispiel mit seinen zwölf Monatswerten sieht die Quelltabelle nun wie in Bild 4 aus und enthält nach jeweils drei Monatsspalten noch eine zusätzliche Spalte zur Anzeige der Quartalssumme. Diese soll natürlich nicht importiert werden, da ihre Daten von den jeweils links daneben befindlichen Spalten abhängig sind und somit in der Datenbank redundant wären.
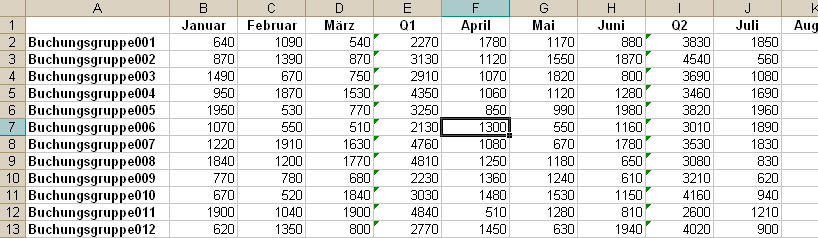
Bild 4: Tabellenblatt für den Import, das zu überspringende Spalten enthält
Statt umständlich auf Beschriftungen wie Q1 in der Kopfzeile zu prüfen, die sich unter Umständen auch ändern, müssen Sie für diesen Fall nur den Ausdruck anpassen, der die Spaltenindizes berechnet:
c = (i - 1) Mod (17 - 4) + 1 r = (i - 1) \ (17 - 4) + 1
Beachten Sie den Ausdruck (17 – 4), der etwa den Ausdruck 13 ersetzt: Eine Kopfspalte plus zwölf Monate plus vier Quartalssummen (der Ausdruck 17 – 4 steht hier natürlich nur zur Verdeutlichung: 17 Spalten, von denen vier wegfallen). Das funktioniert natürlich noch nicht, da so nach wie vor die Zahlenreihe von 1 bis 13, also 1, 2, 3 … 13, erzeugt wird.
Damit alle 17 Spalten unter Auslassung der Summenspalten berücksichtigt werden, ergänzen Sie den Ausdruck wie folgt:
For i = 1 To LastRow * (LastCol - 4)
r = (i - 1) \ (17 - 4) + 1
c = (i - 1) Mod (17 - 4) + 1
c = c + (c - 2) \ 3
Der so geänderte Code ergibt für c die sich wiederholende Zahlenreihe (1, 2, 3, 4, 6, 7, 8, 10, 11, 12, 14, 15, 16). Ein Blick in Bild 4 zeigt: Es fehlen genau die Spalten, die Sie nicht importieren wollen, nämlich 5 (E, Q1), 9 (I, Q2), 13 (M, Q3) und 17 (Q, Q4). Davon abgesehen verwenden Sie die gleiche Routine wie im vorherigen Beispiel.
Im Detail passiert hier Folgendes: Der Bereich erstreckt sich nun über 17 statt wie vorher 13 Spalten. Aber Sie wollen nach wie vor nur 13 von diesen 17 Spalten importieren, vier werden übergangen. Daher sind immer noch lastRow x 13 Schritte nötig. Das gilt sowohl für den Schleifenkopf, lastCol – 4 ist ja 17 – 4, als auch für die Ausdrücke für r und c.
Der c-Ausdruck erzeugt natürlich dieselbe Ausgabe, wie er das auf Basis 13 auch schon tat, nämlich (1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13).
Ende des frei verfügbaren Teil. Wenn Du mehr lesen möchtest, hole Dir ...
Testzugang
eine Woche kostenlosen Zugriff auf diesen und mehr als 1.000 weitere Artikel
diesen und alle anderen Artikel mit dem Jahresabo