
Zusammenfassung
Das Indizieren kann der Performance zu- oder abträglich sein. Erfahren Sie, wie Sie die Indizierung richtig einsetzen.
Techniken
Tabellen, Indizierung
Voraussetzungen
Access 97 oder höher
Beispieldateien
Dirk Bauer, Düsseldorf
Sie haben zahllose Arbeitsstunden für das Datenmodell Ihrer Anwendung aufgewendet, eine schöne Oberfläche erstellt, viele nette Funktionen implementiert und vor der Freigabe der Software alles ausführlich getestet. Trotzdem ist die ausgefeilte Suchabfrage der Daten schon kurz nach der Einführung der Software auf einmal so langsam, dass ein vernünftiges Arbeiten mit der Access-Anwendung nicht mehr möglich scheint. Nun ist es höchste Zeit, sich die Indizes in den Tabellen Ihrer Anwendung anzusehen!
Um den Sinn und Zweck eines Datenbank-Index zu verstehen, sehen Sie sich das folgende Beispiel an: Eine Access-Anwendung enthält eine Tabelle tblMitarbeiter. In dieser Tabelle werden alle Mitarbeiter eines Unternehmens mit ihren üblichen Attributen wie Nachname, Vorname, Telefonnummer und so weiter abgelegt (siehe Bild 1).
In der Anwendung soll es nun möglich sein, über eine Suchmaske den Nachnamen eines Mitarbeiters ganz oder teilweise einzugeben.
Die Anwendung soll anschließend alle Mitarbeiter ausgeben, die dem erfassten Suchbegriff entsprechen.
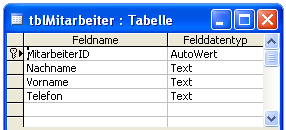
Bild 1: Beispieltabelle „Mitarbeiter“
Ohne weitere Modifikation der Tabelle tblMitarbeiter legt Access für das Textfeld „Nachname“ bei der Definition der Tabellenstruktur keinen Index an. Stellen Sie sich nun vor, dass die Tabelle mit den Daten einiger Mitarbeiter in einer beliebigen Reihenfolge gefüllt wird. Danach führen Sie die erste Suche mit einem beliebigen Nachnamen durch. Welche Schritte führt die Datenbank-Engine von Access nun intern aus, um alle Mitarbeiter mit dem gesuchten Nachnamen zu ermitteln
Das Durchlaufen aller Zeilen einer Tabelle wird „Tablescan“ genannt, da jede einzelne Zeile in dem relevanten Feld nach dem Suchwert „gescannt“ wird. Ein Tablescan ist bei einigen wenigen Datensätzen kein Problem, da nicht besonders viele Daten überprüft werden. Was aber wäre, wenn wir das komplette Telefonbuch einer Großstadt in dieser Tabelle abgelegt hätten
Um das Beispiel nun ein wenig zu modifizieren, sollten Sie sich einmal überlegen, wie Sie einen bestimmten Gesprächspartner aus dem öffentlichen Telefonbuch heraussuchen.
Mit Sicherheit werden Sie nicht jeden Eintrag auf den einzelnen Seiten des Telefonbuches durchlesen, bis Sie Ihren gewünschten Gesprächspartner gefunden haben.
Statt dieser sehr aufwändigen Methode werden Sie normalerweise den Index am oberen Rand jeder Telefonbuchseite verwenden.
Sie kommen auf diese Weise sehr schnell auf die relevante Seite und können dann gezielt nach einigen wenigen Zeilen Ihren Gesprächspartner ermitteln.
Damit Access bei der Abfrage von Daten ebenfalls die Vorteile eines Index verwenden kann, muss für das Textfeld Nachname zunächst ein Index erstellt werden.
Bei der Definition des Index gehen wir weiter davon aus, dass der Index als „aufsteigend sortiert“ angelegt wird. Abb. 2 veranschaulicht die interne Situation nach der Anlage eines Index.
Auf der rechten Seite ist die Mitarbeiter-Tabelle dargestellt. Wir betrachten hier nun lediglich das für die Suche relevante Feld Nachname mit einigen Testdaten.
Links neben der Spalte Nachname ist zur Veranschaulichung die Reihenfolge des jeweiligen Nachnamens dargestellt. So ist zum Beispiel der Nachname „Bauer“ als fünfter Datensatz erfasst. Die Einträge wurden offensichtlich nicht sortiert abgelegt, sondern in einer willkürlichen Reihenfolge.
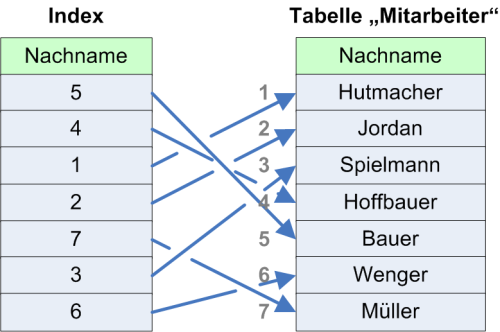
Bild 2: Aufbau eines einfachen Index
Auf der linken Seite ist eine interne, von Access erzeugte Index-Tabelle zu sehen. Der Index wurde mit dem Namen des zu indizierenden Feldes („Nachname“) benannt.
Da der Index aufsteigend sortiert aufgebaut wurde, verweisen die referenzierten Einträge in der Index-Tabelle nun in einer anderen Reihenfolge auf die Mitarbeiter-Tabelle als ursprünglich. Wenn nun zum Beispiel nach allen Einträgen gesucht wird, die mit dem Buchstaben „B“ beginnen, geht Access wie folgt vor:
Binäre Suchbäume
Damit Access bei der Suche nach den relevanten Daten nicht den kompletten Index lesen muss, wird der Index intern als „binärer Suchbaum“ abgelegt.
Ein einfaches Beispiel anhand von Zahlen soll die Arbeitsweise eines solchen Baumes demonstrieren (siehe Bild 3).
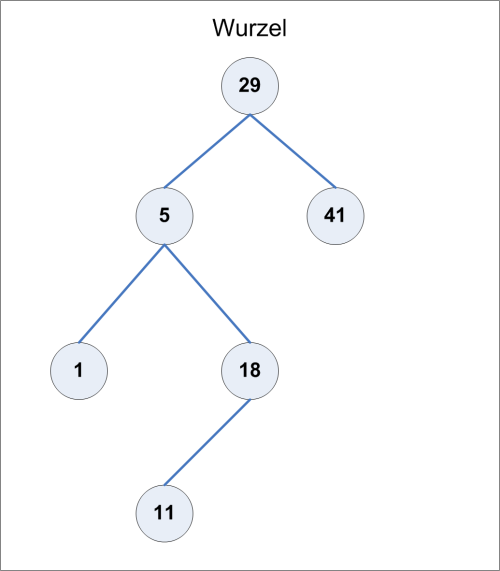
Bild 3: Binärer Suchbaum
Folgende Regeln gelten für binäre Bäume:
Der dargestellte Baum speichert exemplarisch die Zahlenmenge {1, 5, 11, 18, 29, 41}. Die Art der Darstellung ist nur eine von vielen möglichen Darstellungen dieser Menge und zum Beispiel davon abhängig, welche Zahl zuerst gespeichert wurde und wie der Baum in das Gleichgewicht zwischen der linken und der rechten Seite gebracht werden kann.
Im vorliegenden Fall wurde zunächst die Zahl 29 gespeichert und somit automatisch zur Wurzel des Baums.
Wie wird nun beispielsweise der Wert 18 im Baum gefunden Zunächst vergleicht die Jet-Engine die Wurzel (Nummer 29) mit dem Wert 18.
Da der gesuchte Wert 18 kleiner als die Wurzel ist, verzweigt die Jet-Engine auf der Suche gemäß Definition nach links und gelangt zum Knoten 5. Der Wert 18 ist größer als der Wert 5 und somit verschlägt die Suche die Jet-Engine diesmal nach rechts.
Falls der gesuchte Wert weder größer noch kleiner als der aktuelle Knoten ist, handelt es sich um einen Treffer und die Suche ist beendet.
Suchen Sie einen Wert, der nicht im Baum vorkommt – zum Beispiel die Zahl 21 – dann endet die Suche im Knoten mit dem Wert 18. Die gesuchte Zahl müsste nämlich im rechten Teilbaum des Knotens 18 liegen.
Da dieser Teilbaum nicht mehr vorhanden ist, ist die Suche erfolglos und kann ohne weitere Vergleiche abgebrochen werden.
Wenn Sie die Zahl 21 in den Suchbaum einfügen möchten, führt Sie die Suche zunächst wie beschrieben bis zum Knoten mit dem Wert 18. Dann wird der Knoten 21 als Nachfolger von Knoten 18 und als neues Blatt auf der rechten Seite eingefügt.
Bild 4 zeigt den nun aktualisierten Baum mit dem Knoten 21.
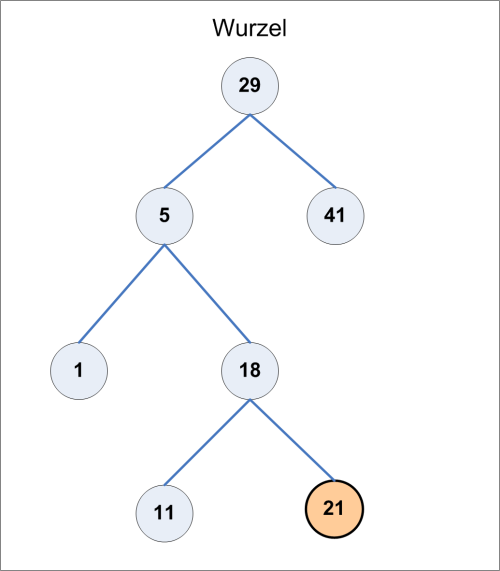
Bild 4: Der binäre Suchbaum mit dem neuen Knoten
Mit der durchgeführten Suche nach der korrekten Stelle zum Einfügen des neuen Knotens in den Baum wird garantiert, dass die Eigenschaften des Suchbaums immer erhalten bleiben.
Wenn Sie sich nun fragen, wozu der ganze Aufwand zur Verwaltung von Daten in einem binären Baum überhaupt durchgeführt wird, sollten Sie die Vorteile dieses Verfahrens einmal genauer betrachten:
Von der Verwaltung eines Index in einem binären Suchbaum hält Access Sie komplett fern. Sie können sich darauf beschränken, (sinnvolle) Indizes für Ihre Datenstrukturen zu definieren, und Access kümmert sich intern um den Rest.
Welche Indexstrategie sinnvoll ist und welche Indizierung möglicherweise Probleme verursachen kann, werden wir später noch detailliert betrachten. Weiterführende Informationen zu binären Suchbäumen können Sie zum Beispiel sehr einfach über die Webseite http://www.wikipedia.de/ recherchieren. Dieser Beitrag kann leider nur einen kleinen Eindruck von der Leistungsfähigkeit und den Möglichkeiten dieser Technik vermitteln.
Um die verschiedenen Anforderungen bei der Indizierung von Daten zu unterstützen, gibt es in Access vier unterschiedliche Index-Typen.
Die in Tab. 1 beschriebenen Typen können teilweise auch noch untereinander kombiniert werden.
Bei der Definition einer Tabelle ermöglicht Access Ihnen eine große Auswahl an Felddatentypen für die Tabellenfelder.
Unser exklusives Angebot für Dich!
(Gilt für den Abschluss eines Jahres-Abonnements im ersten Jahr, danach 189,-/Jahr)
Hier geht’s weiter →Die ersten 4 Wochen kostenlos testen – voller Zugriff auf alle Artikel, vollständigen Code und Beispieldatenbanken. Kein Risiko: Wenn es nicht passt, kündigst Du einfach innerhalb der ersten vier Wochen.
Hast Du eine konkrete Frage zu Deiner eigenen Access-Anwendung?
Vielleicht stellt Deine Anwendung Dich vor eine Herausforderung, zu der Du bisher keine Lösung findest. Schlechte Performance, kein ausreichender Zugriffsschutz, Du bist unsicher über Dein Datenmodell oder Dein Code liefert unerklärliche Fehler?
In unserem kostenlosen Access-Audit schaut sich André Minhorst persönlich gemeinsam mit Dir Deine Lösung per Zoom an – und zeigt Dir, wo Datenmodell, VBA-Code, Ergonomie und Sicherheit Optimierungspotenzial bieten.
Jetzt kostenloses Access-Audit anfordern →