
Alle Jahre wieder tritt der Fall auf, dass die Inhalte eines oder mehrerer PDF-Dokumente eingelesen werden sollen. Diesmal sind es die Kontoauszüge: Ich habe es versäumt, die Buchungsdaten rechtzeitig und regelmäßig per Onlinebanking einzulesen. Da diese in der Regel nur für die vorherigen drei Monate abrufbar sind, stehe ich vor einem Problem. Das Abtippen der in gedruckter Form vorliegenden Auszüge ist selbstverständlich unter der Würde eines Programmierers. Also habe ich mir die PDFs von der Bank zusenden lassen – immerhin ein Eingeständnis.
Lieber wäre es mir natürlich gewesen, wenn die Bank mir die Daten in Form einer Excel-Datei hätte zukommen lassen, aber das ist aus technischen Gründen wohl nicht möglich gewesen. Gut: PDF-Dokumente sind immerhin ein Kompromiss, denn mit ein wenig Fummelei lassen sich auch strukturiert vorliegende Daten auslesen.
Für die in diesem Beitrag beschriebenen Techniken wurde die aktuellste Version von Adobe Reader beziehungsweise Adobe Acrobat verwendet (Version XI beziehungsweise 11.0).
Eine Seite des Kontoauszuges, der eingelesen werden soll, sieht wie in Bild 1 aus. Er besteht aus mehreren Seiten, die immer die gleiche Struktur aufweisen.
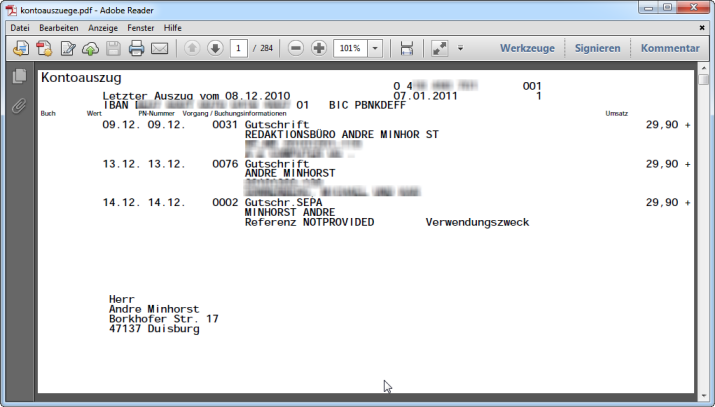
Bild 1: Dieser Kontoauszug soll eingelesen werden.
Welche Möglichkeiten bietet der Adobe Reader, um die enthaltenen Texte einzulesen oder diese zumindest besser einlesbar zu machen
Wenn Sie rechts auf Werkzeuge klicken, erscheinen einige Konvertierungsoptionen etwa nach Word oder Excel (s. Bild 2).
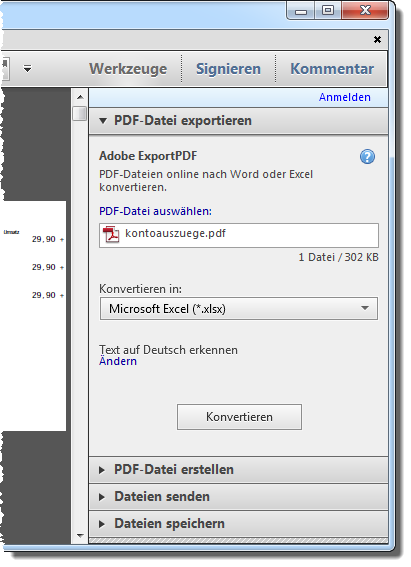
Bild 2: Adobe Reader macht Hoffnung auf eine Vereinfachung, aber …
Allerdings handelt es sich hierbei um einen kostenpflichtigen Onlinedienst, wie Bild 3 zeigt.
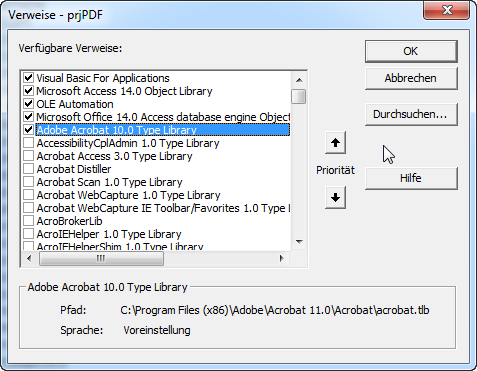
Bild 5: Einbinden der Bibliothek für den Zugriff auf den Acrobat Reader
Die Kosten sind zwar überschaubar, aber wir wissen nicht, wie das Resultat aussehen wird – und außerdem müssen Sie hier gegebenenfalls sensible Daten wie Kontodaten auf den Adobe-Server laden. Das wollen wir nicht und prüfen, welche Möglichkeiten es noch gibt.
Copy and Paste
Die zweite Variante ist es, die Inhalte seitenweise zu markieren, kopieren und etwa in ein Textdokument oder ein Textfeld einzufügen, um diese dann per VBA weiterzuverarbeiten.
Diese Möglichkeit ist allerdings auch nur ein Zwischenschritt – Sie müssen immer noch die gewünschten Informationen aus den Zeilen und Spalten ermitteln.
Außerdem ist Copy and Paste eine nette Sache, wenn es sich um eine begrenzte Anzahl von Operationen handelt – die Kontoauszüge eines Jahres etwa möchte ich persönlich nicht alle von Hand kopieren. Zumal auch die Fehleranfälligkeit mit wachsender Anzahl Vorgänge steigt.
Zugriff per VBA
Der Acrobat Reader liefert eine DLL mit, mit der Sie einige Aktionen ausführen können. Der Zugriff auf den Inhalt einer PDF-Datei gehört leider nicht dazu.
Dazu benötigen Sie den kostenpflichtigen Adobe Acrobat XI Pro. Die Software kann allerdings kostenlos für 30 Tage getestet werden – wer die in diesem Artikel beschriebenen Techniken ausprobieren möchte, kommt damit locker aus.
Die Vorgängerversionen lieferten jeweils eine Schnittstelle, die sich per VBA bedienen ließ. Auch unter Acrobat Reader XI Pro finden Sie im Verzeichnis C:\Program Files (x86)\Adobe\Acrobat 11.0\Acrobat die Datei Acrobat.tlb (s. Bild 4).
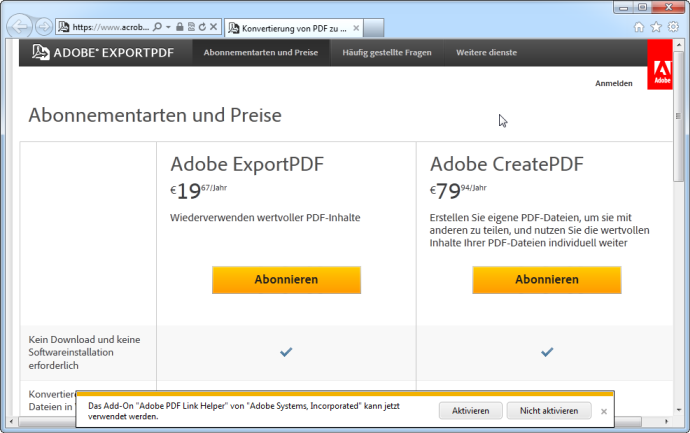
Bild 3: … es handelt sich um eine kostenpflichtige Dienstleistung.
Diese Datei können Sie über den Durchsuchen-Dialog als Verweis in das VBA-Projekt der entsprechenden Datenbankanwendung einbinden (s. Bild 5).
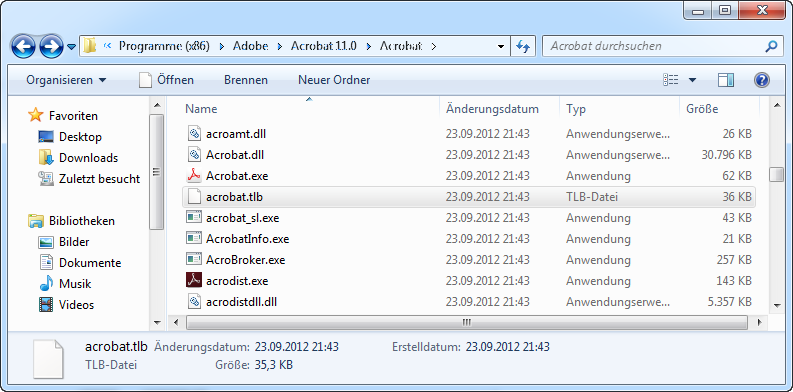
Bild 4: Diese Bibliothek liefert einige Funktionen für die Programmierung der Acrobat-Funktionen.
Seitenzahl auslesen
Mit der folgenden einfachen Prozedur lesen Sie dann ganz einfach beispielsweise die Seitenzahl eines PDF-Dokuments aus:
Public Sub Seitenzahl()
Dim objDocument As Acrobat.AcroPDDoc
Set objDocument = New Acrobat.AcroPDDoc
With objDocument
.Open CurrentProject.Path _
& "\kontoauszuege.pdf"
Debug.Print .GetNumPages
End With
End Sub
Dazu deklarieren und erstellen Sie zunächst ein Objekt des Typs AcroPDDoc, welches auf ein noch zu ladendes Dokument verweist.
Das Laden erledigen Sie mit der Load-Anweisung unter Angabe des Dateipfades. Schließlich liefert die Funktion GetNumPages die Seitenzahl (beim im Beispiel verwendeten Dokument waren es 284 Seiten – viel zu viele, um diese manuell zu durchforsten …).
PDF-Inhalt auslesen
Den eigentlichen Inhalt lesen Sie mit der Prozedur aus Listing 1 aus.
Listing 1: Ausgabe des Inhalts eines PDF-Dokuments im Direktfenster
Public Sub SeiteninhalteAusgeben()
Dim objDocument As Acrobat.AcroPDDoc
Dim objPage As Acrobat.AcroPDPage
Dim objSelect As Acrobat.AcroPDTextSelect
Dim objRect As Acrobat.AcroRect
Dim objPoint As Acrobat.AcroPoint
Dim lngNumText As Long
Dim i As Integer
Set objDocument = New Acrobat.AcroPDDoc
With objDocument
.Open CurrentProject.Path & "\kontoauszuege.pdf"
For i = 0 To .GetNumPages - 1
Set objPage = .AcquirePage(i)
Set objPoint = objPage.GetSize
Set objRect = New Acrobat.AcroRect
objRect.Left = 0
objRect.Top = objPoint.y
objRect.Right = objPoint.x
objRect.bottom = 0
Set objSelect = objDocument.CreateTextSelect(i, objRect)
Debug.Print vbCrLf & "*** Seite " & i
For lngNumText = 1 To objSelect.GetNumText
Debug.Print objSelect.GetText(lngNumText - 1);
Next lngNumText
Next i
.Close
End With
End Sub
Diese Prozedur erzeugt zunächst ein neues Objekt des Typs AcroPDDoc und ruft die Open-Methode auf, um das Quelldokument zu öffnen und zu referenzieren.
Danach durchläuft es eine Schleife über alle Seiten von 0 bis .GetNumPages -1. Die AcquirePage-Methode holt einen Verweis auf die jeweilige Seite.
Interessant ist, dass wir die Inhalte gar nicht unmittelbar auf Basis dieses Objekts des Typs AcroPDPage ermitteln.
Dieses dient nur dazu, ein Objekt des Typs AcroPoint zu füllen. Dies wiederum geschieht mit der Methode GetSize.
Das AcroPoint-Objekt stellt nun zwei Eigenschaften bereit – nämlich die Höhe und die Breite der Seite (x und y).
Diese Eigenschaften benötigen Sie, um den auszulesenden Bereich auf der jeweiligen Seite zu definieren. Diesen legen Sie mit den Eigenschaften Left, Top, Right und Bottom des AcroRect-Objekts fest.
Dabei ist der Nullpunkt des Bereichs links unten, sodass die Werte objPoint.x und objPoint.y den Eigenschaften Right und Top zugewiesen werden.
Damit ausgestattet können Sie mit der Eigenschaft GetNumText die Anzahl der Textelemente des markierten Bereichs ermitteln.
Diese wiederum dient als Bereichsende beim Durchlaufen einer Schleife über alle Textelemente.
Innerhalb dieser Schleife gibt die Debug.Print-Anweisung jeweils den mit der Funktion GetText und der Nummer des zu ermittelnden Textelements gefundenen Text aus.
Der Text der eingangs abgebildeten Seite des Kontoauszugs sieht im Direktfenster beispielsweise wie in Bild 6 aus.
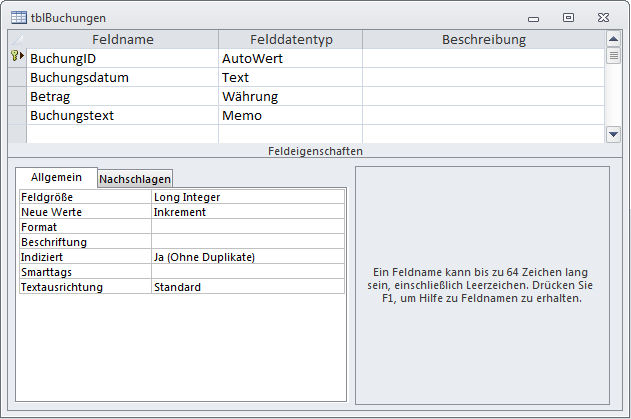
Bild 7: Tabelle zum Speichern der ermittelten Daten
Gewünschte Informationen ermitteln
Nun folgt noch die eigentliche Arbeit – das Ermitteln der Buchungssätze aus den Texten der Kontoauszüge. Diese sollen in der Tabelle tblBuchungen landen, die wie in Bild 7 aussieht.
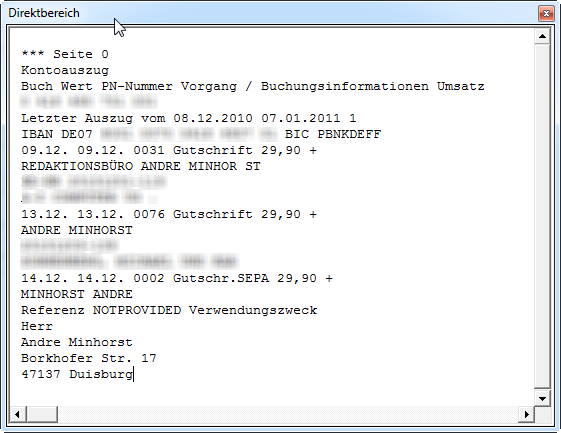
Bild 6: Ausgabe der Prozedur beim Ermitteln des PDF-Texts
Um die Texte der Kontoauszüge zu parsen, müssen Sie diese zunächst analysieren und Regeln aufstellen, wo die Prozedur die wichtigen Informationen findet.
Eine einfache Regel lautet hier: immer dort, wo ein Datum in der Form dd.mm. zu Beginn der Zeile zu finden ist, beginnt ein neuer Buchungsdatensatz.
Die oberen Zeilen des Auszugs wiederholen sich auf jeder Seite und haben eine feste Position. Eventuell kann man sich deren Untersuchung gleich sparen, indem man den Bereich mit dem AcroRect-Objekt entsprechend verkleinert. Dazu misst man entweder das Original-Dokument ab oder findet den richtigen Wert experimentell heraus. Im vorliegenden Fall soll nun nicht mehr das komplette Dokument untersucht werden (y = 300), sondern nur der untere Teil (y = 250). Dazu ersetzen Sie die Zeile
objRect.Top = objPoint.y
durch die folgende Zeile:
objRect.Top = 250
Damit fällt schon einmal der oberste, sich wiederholende Teil des Auszugs weg (s. Bild 8).
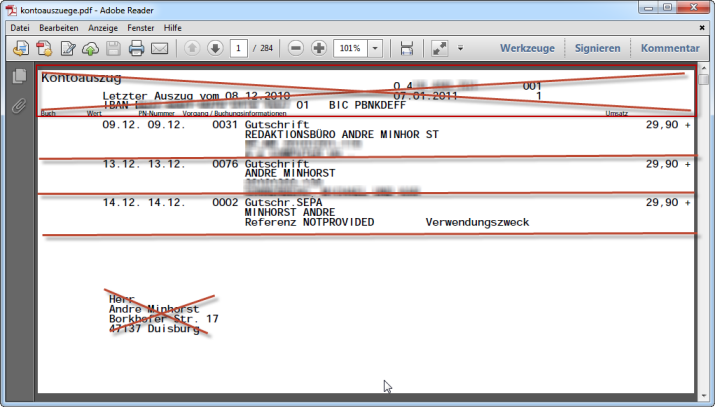
Bild 8: Entfernen von Bestandteilen der Texte und Aufteilen nach einzelnen Buchungen
Danach kümmern wir uns um die auf jeder ersten Seite eines einzelnen Kontoauszugs erscheinende Adresse (das PDF-Dokument enthält mehrere davon).
Beispieldatei
Damit Sie die nachfolgenden Prozeduren selbst ausprobieren können, finden Sie in den Beispieldateien einen teilweise geschwärzten Auszug des verwendeten Kontoauszugs (s. Bild 9).
Bild 9: Geschwärztes Beispieldokument
Unser exklusives Angebot für Dich!
(Gilt für den Abschluss eines Jahres-Abonnements im ersten Jahr, danach 189,-/Jahr)
Hier geht’s weiter →Die ersten 4 Wochen kostenlos testen – voller Zugriff auf alle Artikel, vollständigen Code und Beispieldatenbanken. Kein Risiko: Wenn es nicht passt, kündigst Du einfach innerhalb der ersten vier Wochen.
Hast Du eine konkrete Frage zu Deiner eigenen Access-Anwendung?
Vielleicht stellt Deine Anwendung Dich vor eine Herausforderung, zu der Du bisher keine Lösung findest. Schlechte Performance, kein ausreichender Zugriffsschutz, Du bist unsicher über Dein Datenmodell oder Dein Code liefert unerklärliche Fehler?
In unserem kostenlosen Access-Audit schaut sich André Minhorst persönlich gemeinsam mit Dir Deine Lösung per Zoom an – und zeigt Dir, wo Datenmodell, VBA-Code, Ergonomie und Sicherheit Optimierungspotenzial bieten.
Jetzt kostenloses Access-Audit anfordern →