
André Minhorst, Duisburg
Grundlage für die Entwicklung einer professionellen Datenbankanwendung ist eine entsprechende Modellierung des Datenmodells. Die Musterlösungen und Beispieldatenbanken von Access im Unternehmen versuchen, dieser Voraussetzung zu entsprechen. Im vorliegenden Beitrag erfahren Sie nicht nur, welche Grundlagen hinter der Datenmodellierung professioneller Datenbanken stehen, sondern lernen auch die wichtigsten Begriffe im Zusammenhang mit relationalen Datenbanken, referentieller Integrität und Beziehungen zwischen Tabellen kennen.
Eifrige Leser von Access im Unternehmen haben die vorgestellten Musterlösungen und Beispiele nicht kommentarlos hingenommen, sondern auch den dazugehörenden Beitrag gelesen und nachvollzogen.
Da die theoretischen Hintergründe für die jeweilige Gestaltung des zugrunde liegenden Datenmodells nicht in jedem Beitrag komplett aufgeführt werden können, sollen die Grundlagen für professionelle Datenmodellierung an dieser Stelle einmal umfassend vorgestellt werden.
Im vorliegenden Beitrag lernen Sie die ersten drei Normalformen kennen, die dem ersten, provisorischen Entwurf eines Datenmodells den richtigen Kick geben, und Sie erfahren die Grundlagen für die unterschiedlichen Beziehungstypen und finden eine Erklärung der wichtigsten Begriffe der Datenmodellierung wie Master- und Detailtabelle oder Primär- und Fremdschlüssel.
Die Nordwind-Datenbank, die zu jeder der hier besprochenen Access-Versionen gehört und standardmäßig installiert wird, bietet Beispiele für alle gebräuchlichen Arten von Beziehungen. Daher gelten die Beispiele des vorliegenden Beitrags für das Datenmodell – also die Tabellen und Beziehungen – dieser Datenbank.
Hinweis
Falls Sie nicht wissen, wo Sie die Nordwind-Datenbank finden sollen, lassen Sie sich vom Windows Explorer helfen und suchen Sie im Office-Ordner nach der Datei Nordwind.mdb.
„Warum gibt überhaupt Beziehungen“ Das fragt sichso mancher Anwender, der alle für seine Arbeit wichtigen Daten in einer einzigen Tabelle speichert. Alles auf einen Blick – was will man denn noch mehr
Hinweis
Die folgenden Kapitel beschreiben die theoretischen Grundlagen für den Entwurf des Datenmodells einer relationalen Datenbank. Deren Umsetzung setzt voraus, dass Sie sich bereits mit dem Erstellen von Tabellen sowie der Definition von Beziehungen auskennen.
Davon abgesehen, dass sich Datenmodelle komplexer Anwendungen bestimmt nicht übersichtlich in einer einzigen Tabelle darstellen lassen, führt die oft praktizierte Unart, völlig unterschiedliche Daten in einer einzigen Tabelle unterzubringen, zu Redundanzen und in deren Folge zu Inkonsistenzen.
Um dies zu vermeiden, basieren die Datenmodelle der meisten relationalen Datenbanken auf den 1972 von Edgar F. Codd im Artikel „Further normalization of the data base relational model“ veröffentlichten Normalformen. Die Zusammenfassung ersten drei, für relationale Datenbanken besonders wichtigen Normalformen finden Sie in den folgenden Abschnitten.
Die erste Normalform
Tabellen beinhalten oft Felder, die nicht nur eine, sondern mehrere Informationen speichern. Viele Anwender bringen beispielsweise gerne Vor- und Nachnamen in einem einzigen Feld unter (wie z. B. beim Feld Kontaktperson der Tabelle Kunden in der Nordwind-Datenbank). Probleme sind vorprogrammiert – schon die getrennte Sortierung nach Vor- oder Nachname ist nicht ohne Weiteres möglich.
Ein weiteres Beispiel ist das Speichern von mehreren Informationen gleicher Art in einem einzigen Feld – z. B. das Speichern aller Untergebenen eines Mitarbeiters.
Nicht-Profis umgehen mit solchen Methoden gerne die Erstellung weiterer Beziehungen und Tabellen (und damit vermeintliche Mehrarbeit), verursachen damit aber letztlich erheblichen Mehraufwand.
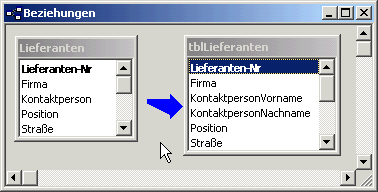
Bild 1: Aufsplittung eines Feldes in seine elementaren Informationen
Die erste Normalform fordert daher, jede relevante Information auch in einzelnen Feldern zu speichern (siehe Bild 1).
Außerdem soll eine Tabelle nicht mehrere gleichartige Daten in unterschiedlichen Feldern enthalten – also in einer Kunden-Tabelle z. B. nicht mehrere Felder für unterschiedliche Kontaktpersonen bereitstellen, sondern die Kontaktpersonen in eine Tabelle auslagern und die Tabellen entsprechend verknüpfen.
Eine weitere Forderung der ersten Normalform ist, dass die Felder einer Tabelle sich lediglich auf die Beschreibung eines einzigen Objekts beziehen – also z. B. auf einen Artikel, einen Kunden, einen Lieferanten oder ähnliche reale Objekte.
Die letzte Forderung ist, auch sich wiederholende Feldinhalte in verknüpfte Tabellen auszulagern. Dies ist sinnvoll, wenn der Inhalt des Feldes aus einer überschaubaren Anzahl von Werten besteht – z. B. den unterschiedlichen Anredeformen für Personen wie Herr, Frau usw. Bei nicht überschaubaren Mengen von möglichen Werten wie z. B. Städtenamen in Adresstabellen ist die Anwendung der ersten Normalform allerdings nicht uneingeschränkt sinnvoll.
Die Nordwind-Datenbank bietet z. B. die Möglichkeit, die Einträge des Feldes Position in der Tabelle Personal in eine weitere Tabelle namens Positionen auszulagern (siehe Bild 2).
Die zweite Normalform
Die zweite Normalform setzt das Bestehen der ersten Normalform voraus und besagt weiterhin, dass jede Tabelle einen Primärschlüssel haben muss und dass alle weiteren Felder nur von diesem einen Primärschlüssel funktionell abhängig sind.
Der Primärschlüssel ist ein Feld oder eine Kombination von mehreren Feldern. Er darf genau einmal in einer Tabelle vorkommen.
Die Bedeutung funktionaler Abhängigkeit lässt sich leicht am Beispiel eines Artikels erläutern: Eine Artikeltabelle enthält einen eindeutigen Index – in der Regel die Artikelnummer – und einige weitere Informationen wie die Bezeichnung des Artikels, den Preis, den aktuellen Bestand usw. Alle diese Informationen beziehen sich genau auf den Artikel mit der jeweiligen Artikelnummer – und sind damit von dem Primärschlüssel Artikel-Nr abhängig.
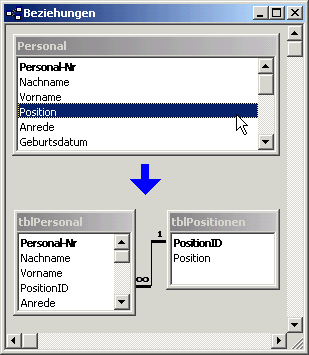
Bild 2: Auslagerung der Position in eine verknüpfte Tabelle
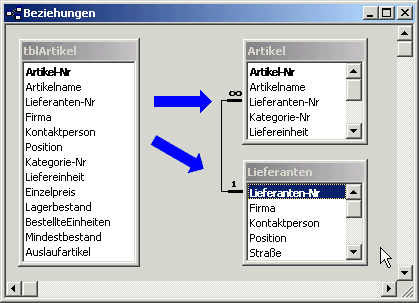
Bild 3: Auslagern von nicht-transitiven Abhängigkeiten
In der Praxis verhindern Sie auf diese Weise, dass sich mehrere völlig gleiche Datensätze in derselben Tabelle befinden.
Die dritte Normalform
Die dritte Normalform setzt das Bestehen der zweiten Normalform voraus und verlangt außerdem die Beseitigung sämtlicher nicht-transitiver Abhängigkeiten.
Nicht-transitive Abhängigkeiten sind funktionale Abhängigkeiten zwischen Feldern der Tabelle, von denen keines der Primärschlüssel dieser Tabelle ist. Das folgende Beispiel verdeutlicht den Zusammenhang:
Möglicherweise enthält die Tabelle aus dem vorherigen Beispiel auch Informationen über den Lieferanten des Artikels in Form der Lieferanten-ID, des Lieferantennamens und einigen weiteren Informationen wie z. B. Adressdaten des Lieferanten (siehe Bild 3).
Wenn Sie sich die Lieferanten-ID als Primärschlüssel für die Lieferantendaten vorstellen, dann sind alle weiteren Lieferantendaten funktional abhängig von der Lieferanten-ID – nicht aber vom eigentlichen Primärschlüssel der Artikeltabelle.
Zur Durchsetzung der dritten Normalform müssten Sie also die Lieferantendaten komplett in eine weitere Tabelle ausgliedern (wie es in der Nordwind-Datenbank der Fall ist) und nur den Primärschlüssel der Lieferantentabelle, also die Lieferanten-ID, als Fremdschlüssel in die Artikeltabelle aufnehmen.
Vorteile der Normalisierung des Datenmodells
Die nachfolgende Auflistung enthält einige wichtige Vorteile der Normalisierung des Datenmodells:
Die drei wesentlichen Vorteile lassen sich am bereits genannten Beispiel beschreiben, bei dem aus einer Artikeltabelle inklusive detaillierter Lieferantendaten zwei Tabellen mit getrennten Artikel- und Lieferantendaten entstehen.
Einmalige Eingabe von Daten
Die Artikeltabelle besteht nur noch aus Feldern, die direkt der Beschreibung des Artikels dienen. Dazu gehört auch ein Feld mit dem Kürzel des Lieferanten als Fremdschlüsselfeld. Dieses Feld beinhaltet einen der in der Lieferantentabelle verwendeten Primärschlüssel und dient damit der Zuordnung des Lieferanten zu dem Artikel. Sie können also jeden eingegebenen Lieferantendatensatz beliebig vielen Artikeldatensätzen zuordnen, ohne die Daten für jeden Artikel neu eingeben zu müssen.
Vermeidung von Redundanzen
Wenn Sie die Artikeltabelle vor der Abspaltung der Lieferantendaten ansehen, können Sie sich sicher vorstellen, dass einige Lieferanten mehrere Artikel liefern. Die Tabelle enthält dann die gleichen Daten direkt mehrfach – ein typischer Fall einer Redundanz. Durch die Abspaltung solcher Daten verhindern Sie solche Redundanzen.
Vermeidung von Inkonsistenzen
Tabellen mit redundanten Daten bergen immer das Risiko der Entstehung von Inkonsistenzen. Eine Inkonsistenz liegt beispielsweise vor, wenn einer von zwei Datensätzen mit redundanten – also eigentlich gleichen – Daten so geändert wird, dass die redundanten Daten nicht mehr gleich sind. Wenn keine redundanten Daten vorkommen, droht die Gefahr der Bildung von Inkonsistenzen erst gar nicht.
Die Wahrung referentieller Integrität bedeutet die Einhaltung einer einzigen Regel: Jeder Fremdschlüsselwert eines Datensatzes einer Tabelle muss einem Primärschlüsselwert eines Datensatzes der verknüpften Tabelle entsprechen.
Um diese Regel mit Leben zu füllen, lernen Sie zunächst die beiden Schlüsselarten Primärschlüssel und Fremdschlüssel kennen und erfahren anschließend, wie sich die Anwendung dieser Regel im praktischen Einsatz einer Datenbank auswirkt.
Schlüsselarten
Im Rahmen des relationalen Datenmodells verwenden Sie zwei unterschiedliche Schlüsselarten, um Beziehungen zu realisieren. Dabei handelt es sich um Primär- und Fremdschlüssel.
Primärschlüssel
Primärschlüssel dienen unter anderem der eindeutigen Definition eines Datensatzes. Sicher gibt es Tabellen, deren Feldzusammensetzung ein Auftauchen zweier identischer Datensätze nahezu ausschließt.
Unser exklusives Angebot für Dich!
(Gilt für den Abschluss eines Jahres-Abonnements im ersten Jahr, danach 189,-/Jahr)
Hier geht’s weiter →Die ersten 4 Wochen kostenlos testen – voller Zugriff auf alle Artikel, vollständigen Code und Beispieldatenbanken. Kein Risiko: Wenn es nicht passt, kündigst Du einfach innerhalb der ersten vier Wochen.
Hast Du eine konkrete Frage zu Deiner eigenen Access-Anwendung?
Vielleicht stellt Deine Anwendung Dich vor eine Herausforderung, zu der Du bisher keine Lösung findest. Schlechte Performance, kein ausreichender Zugriffsschutz, Du bist unsicher über Dein Datenmodell oder Dein Code liefert unerklärliche Fehler?
In unserem kostenlosen Access-Audit schaut sich André Minhorst persönlich gemeinsam mit Dir Deine Lösung per Zoom an – und zeigt Dir, wo Datenmodell, VBA-Code, Ergonomie und Sicherheit Optimierungspotenzial bieten.
Jetzt kostenloses Access-Audit anfordern →