
„Trigger oder nicht Trigger. Das ist hier die Frage.“, wäre wohl die Aussage von Hamlet gewesen, hätte er sich mit Datenbankentwicklung und nicht mit anderen Tragödien beschäftigt. Eine Entscheidung für oder gegen Trigger ist selten unstrittig. Die IT-Branche ist nicht gerade arm, was Grundsatzdiskussionen und Glaubenskriege angeht. Und so hat auch die Datenbankentwicklung ein immer wiederkehrendes Thema: Pro und Contra Trigger. Dies soll nun kein einsamer Monolog für oder gegen Trigger werden, sondern die grundsätzliche Funktionsweise von Triggern erklären und Ihnen einige Informationen liefern, auf deren Grundlage Sie Ihre eigene Meinung bilden können.
Trigger können wie gespeicherte Prozeduren mehrere SQL-Anweisungen enthalten und werden als Objekt zur wiederverwendbaren Ausführung im SQL Server gespeichert. Wie auch bei einer gespeicherten Prozedur wird für einen Trigger bei der ersten Ausführung ein Ausführungsplan erstellt und im Prozedurcache abgelegt. Bei der nächsten Ausführung entfällt die Erstellung des Ausführungsplans, da der im Prozedurcache gespeicherte wiederverwendet werden kann. Insofern nutzen Trigger dieselben Performancevorteile wie gespeicherte Prozeduren.
Hier enden bereits die Gemeinsamkeiten von gespeicherten Prozeduren und Triggern, denn im Gegensatz zu gespeicherten Prozeduren sind Trigger keine eigenständigen Objekte und können nicht manuell aufgerufen werden. Vielmehr werden die im Trigger gespeicherten SQL-Anweisungen als fester Bestandteil einer Tabelle gespeichert.
Einsatzmöglichkeiten von Triggern
Ein Trigger ist immer an eine Tabelle gebunden und wird nur über eine Datenmanipulation – ein Update, ein Insert oder ein Delete – an dieser Tabelle ausgelöst.
Durch diesen Automatismus eignen Trigger sich besonders zur Gewährleistung der Datenkonsistenz und der Einhaltung von Geschäftsregeln.
Nachfolgend einige Beispiele für den Einsatz von Triggern:
- Durchsetzen der referentiellen Integrität: Der SQL Server bietet für die Einhaltung der referentiellen Integrität inklusive der Lösch- und Aktualisierungsweitergabe zwar bereits Standard-Funktionen, jedoch sind diese meist statisch und nicht flexibel.
- Mit einem Trigger können Sie die Prüfung der referentiellen Integrität beziehungsweise der Lösch- und Aktualisierungsweitergabe mit einer flexibleren Funktionalität erweitern und dadurch Datenmanipulationen zulassen, die die normalen Prüfungen eigentlich ausschließen.
- Generieren von komplexen Standardwerten: Im SQL Server können Sie zu jeder Spalte einer Tabelle einen Standardwert definieren. Dieser Wert ist entweder eine Konstante oder er wird mit T-SQL-Funktionen wie getdate() erzeugt.
- Sofern komplexere Standardwerte wie Berechnungen oder Werte aus anderen Tabellen benötigt werden, können diese durch Trigger berechnet beziehungsweise ermittelt werden.
- Einhalten von Regeln bei der Datenverarbeitung: Die Verarbeitung der Daten einer Datenbank unterliegen den Geschäftsregeln und den Regeln zur Datenkonsistenz. Um eine Datenmanipulation zu verhindern, die gegen diese Regeln verstieße, bieten Tabellen die Check Constraints (zu deutsch Einschränkungen). Die Möglichkeiten für Einschränkungen sind aber stark begrenzt, denn zur Prüfung der Eingabe stehen nur die in den Einschränkungen angegebenen Werte und einige wenige T-SQL-Funktionen zur Verfügung. Mit Triggern können die Eingaben flexibler geprüft werden, indem etwa die Eingaben mit Werten aus anderen Tabellen oder aus komplexen Berechnungen verglichen werden.
- Protokollierung von Datenänderungen: Die klassische Anforderung, dass jeder geänderte, gelöschte oder hinzugefügte Datensatz primärer Tabellen in einer anderen Tabelle protokolliert wird, lässt sich mit Triggern umsetzen.
- Redundante Datenhaltung: Redundante Daten werden gerne zur Performance-Steigerung verwendet. Um zum Beispiel die Rechnungssumme schneller zu ermitteln, könnten Sie diese im Rechnungskopf speichern. Die Summe wird anhand der Positionssummen der Rechnung ermittelt. Sofern sich an den Positionen etwas ändert, muss auch die Summe im Rechnungskopf angepasst werden. Wenn aber Redundanz, dann sollte diese schon korrekt und konsistent sein. Diese Konsistenz kann durch einen Trigger sichergestellt werden. Egal ob eine neue Position hinzugefügt, eine bestehende geändert oder gelöscht wird, der Trigger übernimmt die Übertragung der neuen Summe in den Rechnungskopf.
Dies sind nur ein paar Beispiele für den Einsatz von Triggern. Dadurch, dass Sie bis auf wenige Ausnahmen dieselben Möglichkeiten wie bei gespeicherten Prozeduren haben, können Sie mit Triggern sehr viel Logik abbilden. Um einen Trigger zu verwenden, muss dieser zunächst programmiert werden. Wie bereits erwähnt, wird ein Trigger immer dann ausgeführt, wenn an einer Tabelle Daten manipuliert wurden. Aus diesem Grund ist der Quellcode eines Triggers immer fest mit einer Tabelle verbunden.
Elemente eines Triggers
Zu einem Trigger gehört nicht nur die Angabe der Tabelle, sondern auch die Aktion der Datenmanipulation. Ein Trigger reagiert nicht zwangsläufig bei allen Datenmanipulationen, sondern auf solche, für die er auch definiert wurde.
Dabei kann der Trigger nur für eine der drei Aktionen Insert, Delete, Update oder für eine Kombination der drei aktiv werden. Die automatische Ausführung (im Fachjargon „das Feuern“) des Triggers ist nur bei diesen drei Aktionen möglich. Für andere Aktionen der Tabelle, wie Truncate Table, kann kein Trigger definiert werden.
Einer Tabelle können mehrere Trigger anhaften. Es können mehrere Aktionen in einem Trigger behandelt, pro Aktion ein einzelner Trigger und auch mehrere Trigger für eine einzelne Aktion erstellt werden. Es wäre also etwa möglich, für eine Tabelle einen Trigger zu definieren, der nur auf die Aktion Delete reagiert, und noch einen Trigger, der die Aktionen Insert und Update behandelt. Hinzu käme noch ein Trigger für einen besonderen Fall einer Update-Anweisung, der speziell nur dafür eingesetzt wird.
Sofern Sie für eine Aktion mehrere Trigger definiert haben, müssen Sie zusätzlich noch die Reihenfolge der Ausführung der Trigger mit der Systemprozedur sp_settriggerorder festlegen.
Der Trigger selbst enthält verschiedene Prüfungen und Anweisungen. Diese Prüfungen und Anweisungen programmieren Sie in T-SQL. Im Großen und Ganzen kann man die Entwicklung von Triggern mit der Entwicklung von gespeicherten Prozeduren vergleichen. Bei der Programmierung muss jedoch beachtet werden, dass die SQL-Anweisungen immer pro Aktion der Datenmanipulation ausgeführt werden. Insofern sollten auch alle betroffenen Datensätze der Datenmanipulation im Trigger angesprochen werden.
Diese Datensätze stehen innerhalb des Triggers in den virtuellen Tabellen inserted und deleted zur Verfügung. Beide Tabellen besitzen dieselbe Struktur wie die Tabelle des Triggers. Die Tabelle inserted beinhaltet die neuen Datensätze, die durch eine INSERT-Anweisung der Tabelle hinzugefügt wurden, während die Tabelle deleted die durch eine DELETE-Anweisung gelöschten Datensätze enthält. Die UPDATE-Anweisung nutzt beide Tabellen: die Werte vor der änderung stehen in der Tabelle deleted und die Werte nach der änderung in der Tabelle inserted.
Beide Tabellen können innerhalb des Triggers wie SQL Server-Tabellen verwendet werden. Sie können die Daten der Tabellen aggregieren, filtern, sortieren und die Tabellen mit anderen Tabellen verknüpfen und vieles mehr. Nur ändern können Sie die Daten dieser Tabellen nicht.
Trigger sind neben gespeicherten Prozeduren die einzigen SQL Server-Objekte, mit denen Daten manipuliert werden können. Es ist also möglich, in einem Trigger selbst wieder die Befehle Update, Delete und Insert zu verwenden.
Diese können Sie in der Tabelle des Triggers wie auch in anderen Tabellen ausführen. Sie sollten aber bedenken, dass durch diese Datenmanipulationen ebenfalls wieder Trigger ausgelöst werden können, die wiederum durch eigene Datenmanipulationen Trigger auslösen können.
Schließlich ist es sogar möglich, dass der Trigger, der die Datenmanipulation ausführt, durch weitere Trigger nochmals ausgelöst wird. Solche rekursiven Aufrufe sind in einer Tiefe von bis zu 32 Ebenen möglich. Diese Rekursivität wird nicht standardmäßig unterstützt, sondern muss in den Optionen der Datenbank erst aktiviert werden.
Mit Triggern können Sie die manipulierten Daten prüfen und je nach Ergebnis der Prüfung die Manipulation auch verhindern. Um dies dem Benutzer gegenüber transparent zu gestalten, können Sie aus einem Trigger heraus Meldungen ausgeben.
Neben der Ausgabe von Meldungen kann ein Trigger auch noch Daten ausgeben. Was auf den ersten Blick vielleicht selbstverständlich klingt, ist auf den zweiten eher fragwürdig. Denn welche Daten sollte ein Trigger liefern und, vor allem, wohin? Schließlich wird der Trigger bei einer Datenmanipulation an einer Tabelle automatisch ausgeführt und nicht im direkten Kontext einer manuellen Ausführung oder über ein Frontend. Ein wichtiger Punkt wurde bisher noch nicht erwähnt: Der SQL Server bietet zwei Arten von Triggern – den AFTER-Trigger und den INSTEAD OF-Trigger.
AFTER-Trigger
Ein AFTER-Trigger – früher auch als FOR-Trigger bekannt – wird erst nach der Datenmanipulation ausgelöst. Die im Trigger gespeicherten SQL-Anweisungen ergänzen somit die eigentliche Datenmanipulation.
Doch bis zur Ausführung des AFTER-Triggers ist es erst einmal ein weiter Weg. Der Vorgang einer Datenmanipulation teilt sich in mehrere Schritte:
- Die Tabellen inserted und deleted werden erstellt und mit den geänderten, gelöschten oder neu hinzugefügten Daten gefüllt.
- Der INSTEAD OF-Trigger der Tabelle wird ausgeführt, sofern ein solcher definiert ist. Je nach Ergebnis eines INSTEAD OF-Triggers wird die Eingabe abgewiesen und verhindert oder es wird mit den nächsten Schritten der Datenmanipulation fortgefahren.
- Die Prüfungen der Einschränkungen werden durchgeführt. Auch hier kann die Datenmanipulation bereits abgebrochen werden.
- Die referentielle Integrität wird geprüft: Noch ein Schritt, bei dem die Datenmanipulation vorzeitig beendet werden kann.
- Die Daten werden geändert.
- Der AFTER-Trigger wird ausgeführt. Sollten bei der Ausführung des AFTER-Triggers Fehler auftreten, wird die komplette Datenmanipulation verhindert und der Datensatz auf den Zustand vor der Aktion zurückgesetzt.
Ein AFTER-Trigger wird also nicht immer zwangsläufig ausgeführt, denn dazu ist die erfolgreiche Verarbeitung der eigentlichen Datenmanipulation eine unabdingbare Voraussetzung. Dadurch ist der AFTER-Trigger – wie der Name schon sagt – prädestiniert für Aktionen, die nach der vorhergehenden Datenmanipulation folgen müssen.
Mögliche Funktionen von AFTER-Triggern wären etwa die Protokollierung von Datenänderungen oder die Gewährleistung der Datenkonsistenz bei redundanter Datenhaltung, da hier nach der eigentlichen Datenmanipulation eine weitere ausgeführt wird.
Ein INSTEAD OF-Trigger hingegen greift vor der eigentlichen Datenmanipulation ein und ist eher für die Vermeidung oder Korrektur einer solchen zuständig.
INSTEAD OF-Trigger
Während der AFTER-Trigger am Ende der einzelnen Schritte einer Datenmanipulation steht, folgt der INSTEAD OF-Trigger als zweiter Schritt direkt hinter der Erstellung der Tabellen inserted und deleted.
Dies ist notwendig für die grundsätzlichen Aufgaben eines INSTEAD OF-Triggers: Das Prüfen der Datenmanipulation und das damit verbundene Verhindern der Aktion oder das Ersetzen der Werte durch andere, korrekte Werte. Insofern ist ein INSTEAD OF-Trigger optimal für die Prüfung von Dateneingaben, das Durchsetzen der referentiellen Integrität, das Erstellen von komplexen Standardwerten oder die Prüfung von aufwendigen Einschränkungen.
Ein INSTEAD OF-Trigger erweitert also nicht den Vorgang der eigentlichen Datenmanipulation, sondern ersetzt diesen durch seine eigenen SQL-Anweisungen. Für die Datenmanipulation ist nun nicht mehr die eigentliche Aktion mitsamt den dort geänderten Daten maßgebend, sondern die SQL-Anweisungen im INSTEAD OF-Trigger.
Im Gegensatz zu einem AFTER-Trigger können Sie pro Update, Delete oder Insert nur einen INSTEAD OF-Trigger definieren. Neben dem Ausführungszeitpunkt ist dies auch schon der einzige Unterschied zum AFTER-Trigger. Die Entwicklung beider Typen ist identisch.
Entwickeln eines Triggers
Für die Schreiben eines Triggers kann das SQL Server Management Studio verwendet werden. Die Trigger einer Tabelle finden Sie unterhalb der jeweiligen Tabelle im Knoten Trigger. Dort sehen Sie im Kontextmenü auch den Eintrag Neuer Trigger zum Anlegen eines neuen Triggers (s. Abb. 1).
Abb. 1: Ein neuer Trigger
Das SQL Server Management Studio bietet Ihnen zur Erstellung eines Triggers keinen Abfragedesigner. Wie schon bei den gespeicherten Prozeduren erhalten Sie lediglich ein neues Abfragefenster mit einer Skriptvorlage; in diesem Fall mit einer Vorlage zur Anlage eines neuen Triggers.
Einen neuen Trigger legen Sie mit der Anweisung CREATE TRIGGER an. Dazu müssen Sie nicht nur den Namen des Triggers angeben, sondern mit der Option ON auch die Tabelle, an die dieser Trigger gebunden ist. Als weitere Voraussetzung müssen der Typ – AFTER oder INSTEAD OF -, sowie die Aktion(en) Insert, Delete oder Update angegeben werden.
Anschließend wird die eigentliche Programmlogik durch AS eingeleitet und im BEGIN…END-Block zusammengefasst. Dort können Sie Ihren Ideen freien Lauf lassen, sofern diese nicht gegen die Regeln von T-SQL verstoßen oder der Logik der Trigger-Entwicklung widersprechen.
Den ersten T-SQL-Befehl in Ihrem Trigger bietet Ihnen die Vorlage auch schon direkt an: SET NOCOUNT ON. Sie sollten dieses Angebot unbedingt annehmen, da diese Anweisung die Ausgabe der Meldungen xx rows affected zu den DONE_IN_PROC-Anweisungen unterbindet. Access hat je nach Version und eingesetztem Treiber mit diesen Rückmeldungen so seine Probleme. Doch dazu später mehr.
Als Erstes lernen Sie die Umsetzung eines klassischen AFTER-Triggers kennen: Die in der Northwind-Datenbank vergebenen Rabatte von 10 bis 25 Prozent bei den Bestellpositionen sollen in einer eigenen Tabelle protokolliert werden.
Diese Tabelle wird den Abteilungsleitern als Grundlage zu Auswertungen dienen. Um ihnen die Auswertung etwas zu erleichtern, werden die Bestellnummer, Kundennummer, Artikelnummer, Einzelpreis, Menge und Rabatt, sowie die Mitarbeiter-ID des Verkäufers und die Mitarbeiter-ID des Vorgesetzten in der Tabelle protokolliert.
Doch vorab benötigen Sie für dieses Beispiel noch die Tabelle zur Protokollierung der Daten. Listing 1 zeigt das CREATE TABLE-Skript, mit dem Sie diese Tabelle anlegen können.
Listing 1: Tabelle zur Protokollierung
CREATE TABLE dbo.OrdersLog ( LdfNr int NOT NULL IDENTITY(1,1), Controller int NOT NULL, EmployeeId int NOT NULL, CustomerId varchar(5) NOT NULL, OrderId int NOT NULL, ProductId int NOT NULL, UnitPrice money, Quantity smallint, Discount real )
Im Trigger selbst müssen nur die betroffenen Datensätze, also jene mit Rabatten zwischen 10 und 20 Prozent, in die neue Tabelle geschrieben werden. Listing 2 zeigt die SQL-Anweisungen für diese Protokollierung.
Listing 2: Protokollierungs-Trigger
ALTER TRIGGER [dbo].[trg_Discount] ON [dbo].[Order Details] AFTER UPDATE, INSERT AS BEGIN SET NOCOUNT ON; IF UPDATE (Discount) BEGIN IF (select max(Discount) from inserted inner join dbo.orders on inserted.orderid = dbo.orders.orderid inner join employees on dbo.orders.employeeid = dbo.employees.employeeid where reportsto is not null) > '0.25' BEGIN RAISERROR (N'Es darf maximal ein Rabatt von 0.25 gewährt werden!',10,1); ROLLBACK TRAN END END END;
Die Protokollierung besteht aus einer einzigen INSERT-Anweisung. Soweit ist der Code des Triggers nichts wirklich Neues für Sie. Aber eine Besonderheit bietet dieser Code dennoch: Im Trigger wird die Funktion Update() verwendet.
Mit dieser nur in Triggern verfügbaren Funktion wird geprüft, ob der Wert der dort angegebenen Spalte verändert wurde – vorausgesetzt jedoch, die dort angegebene Spalte befindet sich auch in der manipulierten Tabelle.
Die Existenz der angegebenen Spalte wird nur bei der Ausführung des Triggers geprüft, jedoch nicht beim Anlegen oder ändern des Triggers. Sie sollten also die Schreibweise der Spalte vor dem Speichern des Triggers nochmals genau prüfen.
Einen neuen Trigger speichern Sie durch die Ausführung des Skripts. Für nachträgliche änderungen am Trigger müssen Sie den CREATE TRIGGER-Befehl zu einem ALTER TRIGGER ändern, da nur mit diesem Befehl bestehende Trigger verändert werden können.
Nach dem Speichern und der Neuanlage des Triggers trg_OrdersLog möchten Sie diesen bestimmt testen. Den Trigger können Sie durch das Anlegen eines neuen Datensatzes oder durch das ändern eines bestehenden Datensatzes in der Tabelle Order Details auslösen. In beiden Fällen muss zur Protokollierung allerdings ein Discount zwischen 0,10 und 0,25 eingegeben werden.
Die erste SQL-Anweisung, die Sie zum Test eingeben können, legt einen neuen Datensatz in der Tabelle Order Details an:
INSERT INTO dbo.[Order Details] VALUES(11077, 77, €š6.5€, 5, €š0.14€)
Der AFTER-Trigger hat nach diesem Insert dann in der Tabelle OrdersLog die erste Protokollierung angelegt. Um es dem Anwender nicht zu einfach zu machen, die Protokollierung zu umgehen, werden auch nachträgliche änderungen an einem Rabatt protokolliert, sofern dieser zwischen 10 und 25 Prozent liegt.
Dies können Sie mit einer Update-Anweisung an dem neu hinzugefügten Datensatz testen:
UPDATE dbo.[Order Details] SET Discount = €š0.14€ WHERE OrderId = 11077 AND ProductId = 77
Auch diese Datenmanipulation wurde in der Tabelle OrdersLog protokolliert. Die Einträge werden nach folgender SELECT-Anweisung ausgegeben:
SELECT * FROM dbo.OrdersLog
In Abb. 2 sehen Sie das Ergebnis dieser Prüfung.
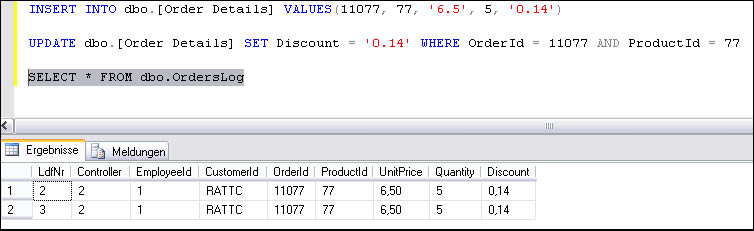
Abb. 2: Die Protokollierung
So weit, so gut. Was aber, wenn der Benutzer nun mehr als 25 Prozent Rabatt gewährt? Einen solchen Rabatt möchte der Abteilungsleiter erst gar nicht in seiner Auswertung sehen, sondern diese Eingabe soll von vornherein vermieden werden. Dafür brauchen Sie keinen Trigger, denn diese Anforderung kann bereits mit einer Einschränkung realisiert werden.
Und wenn diese Regelung nur für Mitarbeiter gilt, nicht aber für den Chef selbst? Für eine solche Anforderung reicht die Funktion einer Einschränkung nicht aus, denn hierzu muss zunächst geprüft werden, ob der Benutzer einfacher Mitarbeiter oder der Chef des Hauses ist. Diese Anforderung kann entweder mit einem AFTER-Trigger oder mit einem INSTEAD OF-Trigger realisiert werden.
Die Geschäftsregel wird bei einem AFTER-Trigger erst nach der bereits durchgeführten Datenmanipulation geprüft. Insofern muss die Aktion bei Verletzen der Regel wieder rückgängig gemacht werden.
Unser exklusives Angebot für Dich!
(Gilt für den Abschluss eines Jahres-Abonnements im ersten Jahr, danach 189,-/Jahr)
Hier geht’s weiter →Die ersten 4 Wochen kostenlos testen – voller Zugriff auf alle Artikel, vollständigen Code und Beispieldatenbanken. Kein Risiko: Wenn es nicht passt, kündigst Du einfach innerhalb der ersten vier Wochen.
Hast Du eine konkrete Frage zu Deiner eigenen Access-Anwendung?
Vielleicht stellt Deine Anwendung Dich vor eine Herausforderung, zu der Du bisher keine Lösung findest. Schlechte Performance, kein ausreichender Zugriffsschutz, Du bist unsicher über Dein Datenmodell oder Dein Code liefert unerklärliche Fehler?
In unserem kostenlosen Access-Audit schaut sich André Minhorst persönlich gemeinsam mit Dir Deine Lösung per Zoom an – und zeigt Dir, wo Datenmodell, VBA-Code, Ergonomie und Sicherheit Optimierungspotenzial bieten.
Jetzt kostenloses Access-Audit anfordern →