
Auch wenn Access und die Jet-Engine bereits zahlreiche Möglichkeiten einer „richtigen“ Datenbank enthalten, fehlen immer noch wichtige Funktionen: So finden Sie etwa beim Umstieg auf SQL Server-Backends viel Bekanntes, aber auch Unbekanntes – zum Beispiel Trigger. Im vorliegenden Beitrag stellen wir den Nutzen von und den Umgang mit Triggern vor.
Welche Aufgaben haben Trigger im SQL Server eigentlich Laut übersetzungshilfe beschreibt das Substantiv „Trigger“ den Auslöser, den Anstoß oder den Abzugsbügel und das Verb entsprechend ansteuern, auslösen, einleiten.
Ein Trigger löst also bei bestimmten Aktionen etwas aus. Da wir uns im SQL Server befinden, kann also nur ein SQL-Befehl etwas auslösen und das kann hier natürlich auch nur wieder ein SQL-Statement sein. Damit realisieren Trigger etwa die Funktionalität, die wir vom Client und dabei etwa aus Access als VBA-Ereignisprozedur kennen. Mit Ereignisprozeduren können Sie beispielsweise beim Einfügen eines Datensatzes eine Aktion auslösen und diesen Vorgang unter bestimmten Bedingungen abbrechen (s. Listing 1).
|
Listing 1: Eine Ereignisprozedur in VBA |
|
Private Sub Form_BeforeInsert(Cancel As Integer) If Name = "Doofmann" Then MsgBox "Solche Namen wollen wir hier nicht!" Cancel = True End If End Sub |
Die unterschiedlichen Client-Programmierumgebungen unterstützen unterschiedliche Ereignisse. Was in VBA unter Access geht, ist vielleicht unter ADO.NET nicht verfügbar, und andersherum, unter ADO und C++ wiederum finden Sie wieder ganz andere Möglichkeiten.
Wenn aber die unterschiedlichen Clients solche Funktionen kennen, warum brauchen wir sie dann noch einmal im SQL Server In einer richtigen Client-Server-Umgebung ist es eben nicht sichergestellt, dass alle Veränderungen an den Daten einer Datenbank über denselben Client abgewickelt werden. Wenn Sie eine Access-Anwendung auf einer SQL Server 2005-Datenbank programmieren und vor dem Löschen eines Datensatzes diesen unbedingt in eine „Ist-gelöscht-worden“-Tabelle schreiben möchten, dann ist die Ereignisprozedur in Access nicht der richtige Weg, da jeder Berechtigte direkt auf die SQL Server-Datenbank zugreifen und ein DELETE FROM tblMeineDaten WHERE ID=9 absetzen kann. Der Datensatz wäre ohne Dokumentation verschwunden (die Syntax „DELETE * FROM…“, also mit „*“ ist im übrigen Access-Dialekt und nicht ANSI SQL).
Die Funktionalität wird also vom Client auf den Server verschoben. ähnliches kennen Sie schon von der referentiellen Integrität. Auch das Löschen von Master-Datensätzen bei existierenden Detail-Datensätzen kann man mit einer client-seitigen Ereignisprozedur überwachen und gegebenenfalls verhindern, doch Access kann dies auch automatisch unterlassen.
Im SQL Server haben Sie noch viel mehr Möglichkeiten: Angenommen, Sie möchten die erwähnte Funktionalität umsetzen und jeden Datensatz vor dem Löschen in eine Dokumentations- oder Historisierungstabelle schreiben, dann sind Trigger genau das Richtige für Sie.
Zum Nachvollziehen der Beispiele bauen Sie am besten direkt eine kleine Testdatenbank auf. Dazu können Sie das Skript aus Listing 2 verwenden, das Sie am einfachsten über das SQL Server Management Studio des SQL Servers 2005 eingeben und ausgeführen (weitere Informationen siehe [1]). Die Syntax wird aber auch vom SQL Server 2000 unterstützt, die ersten Beispiele können Sie daher auch auf diesem nachvollziehen und das Skript beispielsweise im Query Analyser des SQL Servers 2000 ausführen. Wenn Sie die Beispiele wieder löschen wollen, löschen Sie einfach die gesamte Test-Datenbank mit dem Befehl DROP DATABASE TestTrigger. Falls Sie die Fehlermeldung erhalten, dass die Datenbank nicht gelöscht werden kann, weil sie in Benutzung ist (wahrscheinlich von Ihnen selbst durch die Tests), hilft der folgende kleine Trick beim Schließen aller bestehenden Verbindungen:
USE master go ALTER DATABASE TriggerTest SET SINGLE_USER WITH ROLLBACK IMMEDIATE go DROP DATABASE TriggerTest
Das Skript aus Listing 2 erledigt Folgendes: Der Befehl USE wechselt den aktuellen Datenbankkontext, weil es im SQL Server in einer Instanz mehrere Datenbanken geben kann (und meistens auch gibt). Nach dem Erstellen der Datenbank TestTrigger erstellt das Skript mit der CREATE TABLE-Anweisung zwei Tabellen. Die erste Tabelle MyData enthält die Ausgangsdaten, die zweite Tabelle MyDataHistory soll die Löschvorgänge mit Uhrzeit (DEFAULT entspricht dem Standardwert eines Feldes unter Access) und aktuellem Benutzer dokumentieren. Der Befehl GO beendet einen Batch, wobei zur Vereinfachung beinahe alle Befehle in einem einzigen Batch untergebracht sind. Die Anweisungen können dann einzeln markiert und nacheinander ausgeführt werden (wenn Sie F5 oder STRG+E drücken, wird sowohl im Query Analyser des SQL Server 2000 als auch im SQL Server Management Studio des SQL Server 2005 nur die Markierung ausgeführt).
|
Listing 2: Erstellen der benötigten Objekte für die Beispiele |
-- SETUP der Beispieldatenbank ---------- USE master go CREATE DATABASE TriggerTest GO USE TriggerTest GO CREATE TABLE MyData ID int identity Primary Key, Name nvarchar(80) ) GO INSERT INTO MyData VALUES ('Müller')
INSERT INTO MyData VALUES ('Maier')
INSERT INTO MyData VALUES ('Schmidt')
INSERT INTO MyData VALUES ('Schulz')
INSERT INTO MyData VALUES ('Schäfer')
GO SELECT * FROM myData GO CREATE TABLE MyDataHistory ID int, Name nvarchar(80), DeletedAt datetime DEFAULT GETDATE(), DeletedFrom nvarchar(80) DEFAULT SYSTEM_USER ) |
Ein einfacher Trigger
Einen Trigger erstellt man wie andere Objekte in SQL mit dem CREATE-Befehl, hier mit CREATE TRIGGER. Trigger wie der geplante werden immer für eine bestimmte Tabelle erstellt. Diese Tabelle legt man mit dem Schlüsselwort ON fest (s. Listing 3).
|
Listing 3: Erstellen eines einfachen Triggers |
|
CREATE TRIGGER DataHistory ON myData FOR DELETE AS BEGIN INSERT INTO MyDataHistory (ID, Name) SELECT ID, Name FROM deleted END |
Beachten Sie das Schlüsselwort FOR DELETE. Genauso können Sie auch Trigger für das Einfügen und ändern erstellen, dann verwenden Sie das Schlüsselwort FOR INSERT oder FOR UPDATE. Es gibt auch gleichnamige gemeinsame Trigger.
Löschen Sie nun mit den folgenden Anweisungen einmal ein paar Datensätze:
DELETE FROM MyData where ID=2 DELETE FROM MyData where ID=5 GO
Schauen Sie sich das Ergebnis in den beiden Tabellen an:
SELECT * FROM myData SELECT * FROM myDataHistory
Interessant ist hier der Befehl, der im Trigger selbst ausgeführt wird: INSERT INTO… SELECT … FROM deleted. Um welche Tabelle handelt es sich denn bei deleted
Dies ist keine tatsächlich im SQL Server vorhandene Tabelle. Die Abfrage SELECT * FROM deleted wird vom SQL Server dementsprechend mit der Fehlermeldung Invalid object name 'deleted“ beantwortet.
Die Trigger-Tabellen
Der SQL Server stellt die Tabelle deleted allein im Kontext eines Triggers bereit und auch nur für die Dauer der Durchführung des Triggers. Es handelt sich tatsächlich um eine Tabelle, wenn auch keine im üblichen Sinne, und nicht etwa um einen einzelnen Datensatz, denn in einem SQL-Statement können durchaus mehrere Datensätze gelöscht werden. Für jedes Statement wird der Trigger aber nur einmal ausgelöst. Wenn Sie drei Datensätze wie im unten stehenden Listing löschen, wird der Trigger trotzdem nur einmal ausgelöst, die Tabelle deleted enthält dann eben drei Datensätze, wie wir einfach nachweisen können.
Bemerkenswert ist, dass der SQL Server beim Löschen von Datensätzen auch zwei Meldungen erzeugt (siehe Bild 1). (3 row(s) affected) bezieht sich bei der ersten Meldung auf das Einfügen in die History-Tabelle und bei der zweiten Meldung auf den Löschvorgang in MyData. Ob dies tatsächlich die richtige Reihenfolge ist, lässt sich leicht prüfen. Dazu ändern Sie den Trigger wie folgt, was dazu führt, dass der Datensatz mit dem Wert Beethoven für das Feld Name nicht in die History-Tabelle geschrieben wird.
ALTER TRIGGER [dbo].[DataHistory] ON [dbo].[MyData] FOR DELETE AS BEGIN INSERT INTO MyDataHistory (ID, NAME) SELECT ID, Name FROM deleted WHERE Name<>'Beethoven' END
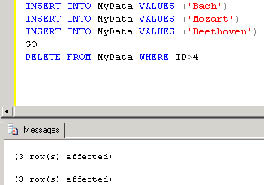
Bild 1: Ausgabe im SQL Server Management Studio
Dementsprechend sollten nun beim Löschen dreier Datensätze zwei Meldungen erscheinen, von denen die eine drei und die andere zwei Datensätze betrifft. Wie Bild 2 zeigt, führt der SQL Server tatsächlich zunächst die im Trigger enthaltenen Operationen und erst dann den eigentlichen Löschvorgang durch.
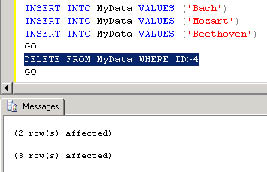
Bild 2: Der Trigger fügt erst die gelöschten Datensätze ein und löscht diese dann aus der Originaltabelle.
So jedenfalls scheint es. Die Aktion des Triggers wird aber laut Dokumentation erst nach der eigentlichen Aktion des SQL-Statements ausgeführt. Alle Trigger im SQL Server 2000 und 2005 sind standardmäßig AFTER-Trigger. Das Schlüsselwort FOR ist dabei gleichbedeutend mit AFTER.
INSERT- und UPDATE-Trigger
Wir haben bislang immer mit einem DELETE-Trigger experimentiert, wie verhalten sich die anderen DML (Data Manipulation Language)-Trigger, die beim Einfügen (Insert) und Aktualisieren (Update) ausgeführt werden
Im Prinzip genauso, nur werden unterschiedliche Tabellen innerhalb der Trigger vom SQL Server verwaltet. Um dies nachzuvollziehen, erweitern wir die History-Tabelle um einen Eintrag, der anzeigt, ob die Daten gelöscht, eingefügt oder geändert wurden (s. Listing 4).
|
Listing 4: Historisieren eingefügter Datensätze |
ALTER TABLE MyDataHistory ADD Type nvarchar(8) GO UPDATE MyDataHistory SET Type='delete' GO ALTER TRIGGER dbo.DataHistory ON dbo.MyData FOR DELETE AS BEGIN INSERT INTO MyDataHistory (ID, Name, Type) Select ID, Name, 'delete' FROM deleted END GO CREATE TRIGGER dbo.InsertHistory ON dbo.MyData AFTER INSERT AS BEGIN INSERT INTO MyDataHistory (ID, Name, Type) Select ID, Name, 'insert' FROM inserted END GO INSERT INTO MyData VALUES ('Wagner')
GO SELECT * FROM MyData SELECT * FROM MyDataHistory |
Wie Sie sehen, wird beim Einfügen innerhalb des INSERT-Triggers eine Tabelle inserted bereitgestellt. Und beim UPDATE-Trigger Falsch geraten! Es gibt keine Tabelle namens updated. Stattdessen benutzt der Update-Trigger beide von den anderen Triggern verwendeten Tabellen. In der Tabelle inserted werden die neuen Werte abgelegt und in der Tabelle deleted die gelöschten (s. Listing 5).
|
Listing 5: Update-Trigger greifen auf die beiden Tabellen deleted und inserted zu. Access im Unternehmen
Unser exklusives Angebot für Dich!Access im Unternehmen
13,25 €
im Monat*
(Gilt für den Abschluss eines Jahres-Abonnements im ersten Jahr, danach 189,-/Jahr) Hier geht’s weiter →Die ersten 4 Wochen kostenlos testen – voller Zugriff auf alle Artikel, vollständigen Code und Beispieldatenbanken. Kein Risiko: Wenn es nicht passt, kündigst Du einfach innerhalb der ersten vier Wochen. Hast Du eine konkrete Frage zu Deiner eigenen Access-Anwendung?Vielleicht stellt Deine Anwendung Dich vor eine Herausforderung, zu der Du bisher keine Lösung findest. Schlechte Performance, kein ausreichender Zugriffsschutz, Du bist unsicher über Dein Datenmodell oder Dein Code liefert unerklärliche Fehler? In unserem kostenlosen Access-Audit schaut sich André Minhorst persönlich gemeinsam mit Dir Deine Lösung per Zoom an – und zeigt Dir, wo Datenmodell, VBA-Code, Ergonomie und Sicherheit Optimierungspotenzial bieten. Jetzt kostenloses Access-Audit anfordern → |